01-Einführung
Angewandte Statistik – Ein Praxiskurs
2025-12-13
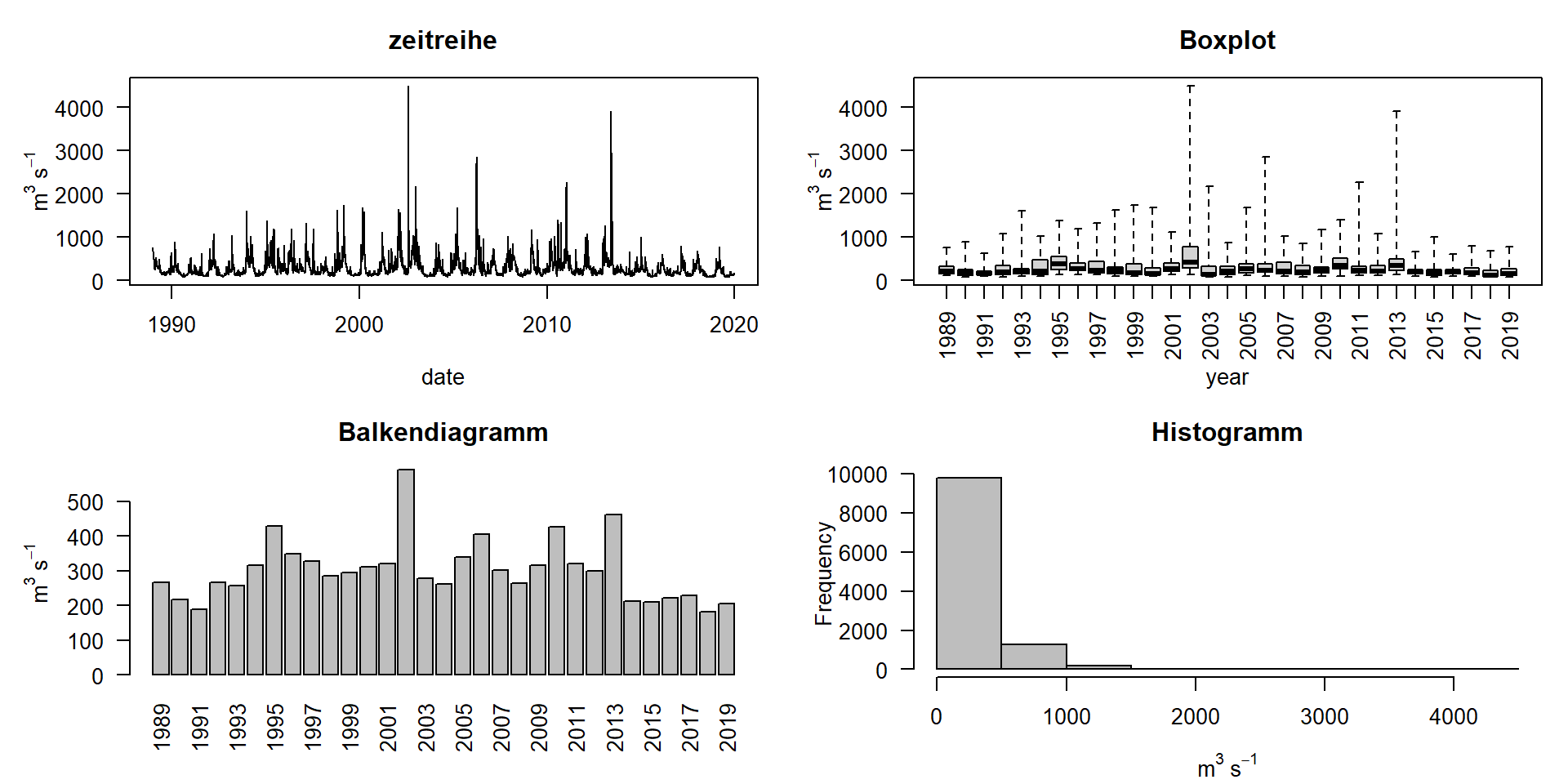
Grafik über 20 Jahre
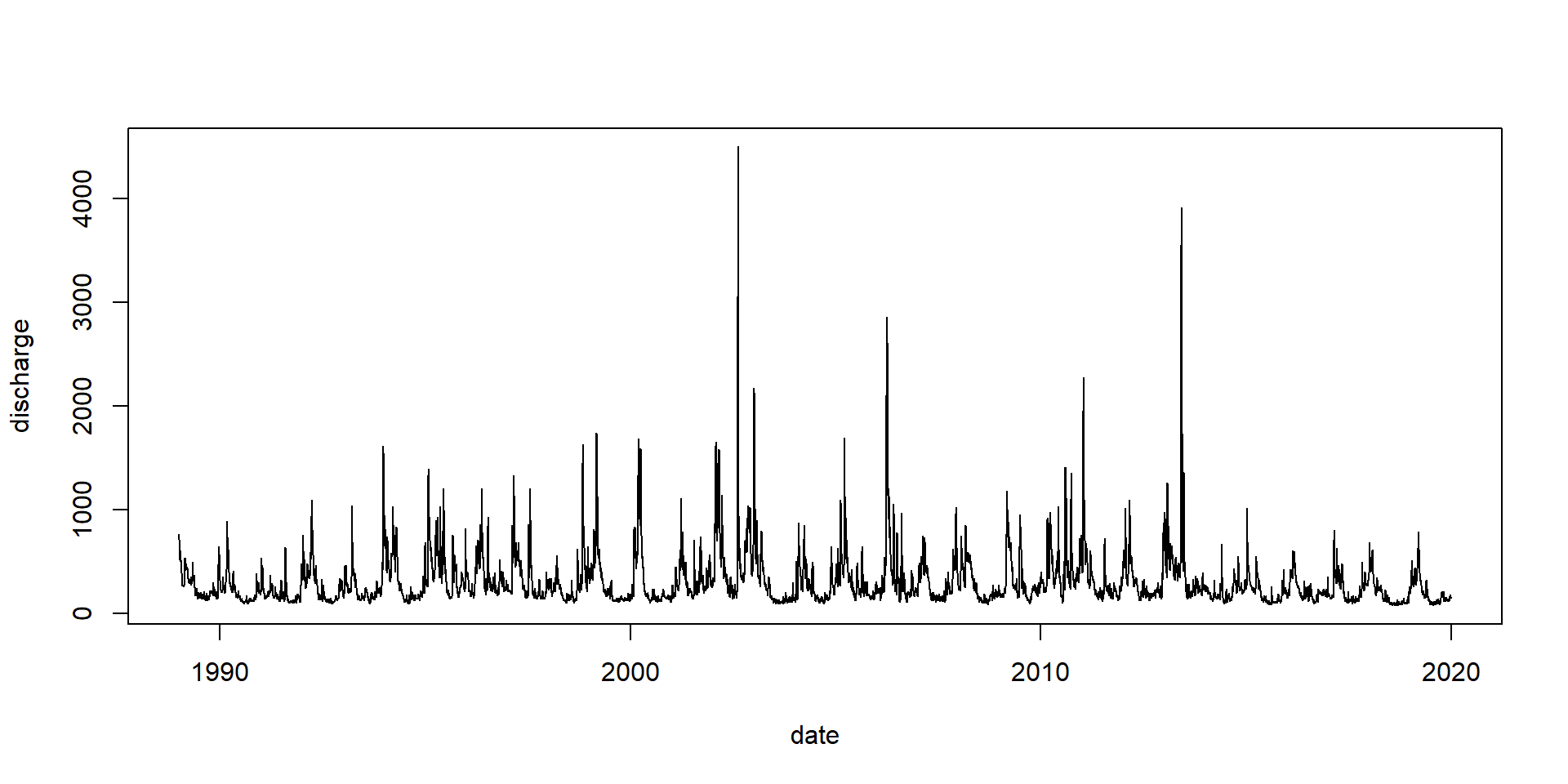
Abfluss der Elbe, Pegel Dresden, Datenquelle BfG
Was sagen uns diese Daten?
- Wie hoch ist der mittlere Abfluss? → Mittelwerte
- Wie groß ist die Variation in den Daten? → Varianz
- Wie wahrscheinlich sind Dürren oder Überschwemmungen? → Verteilung
- Wie präzise sind unsere Vorhersagen? → Konfidenzintervalle
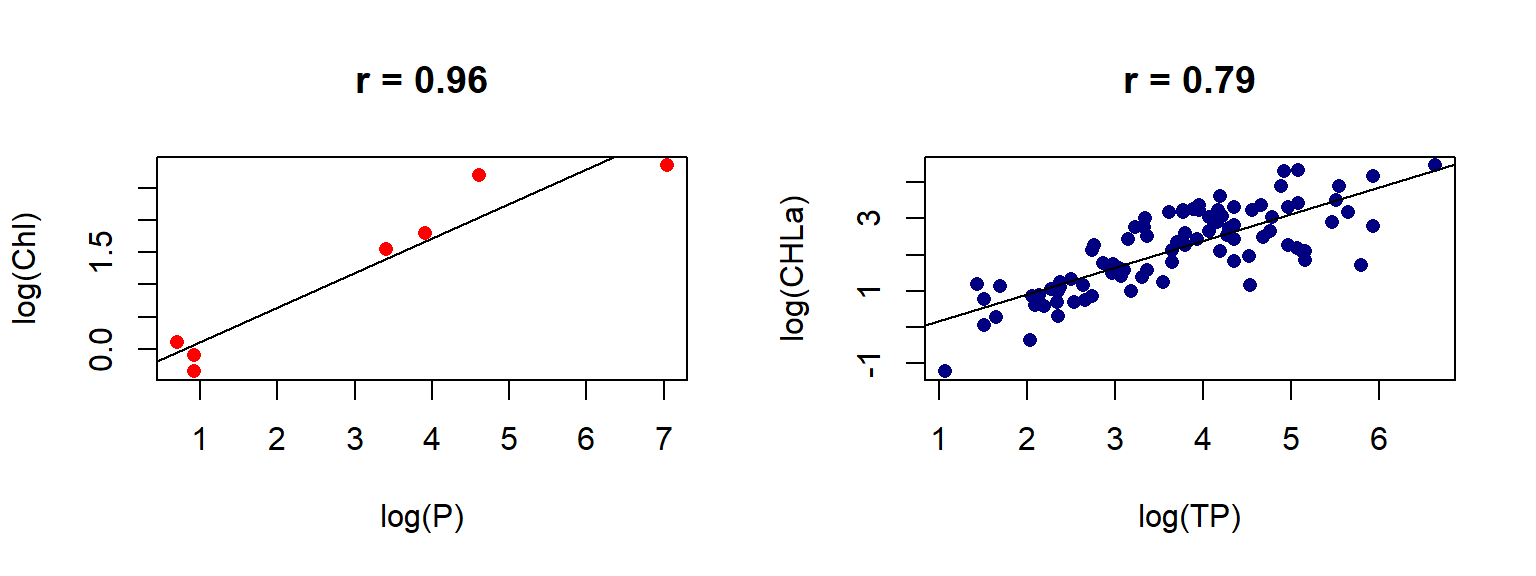
- Welche Faktoren beeinflussen den Abfluss? → Korrelationen
Wie soll man anfangen?
- Mittelwert: 224
- Median: 224
- Standardabweichung: 253
- Spannweite: 2, 4500
Welche dieser Parameter sind am besten geeignet?
Grafiken
Boxplots
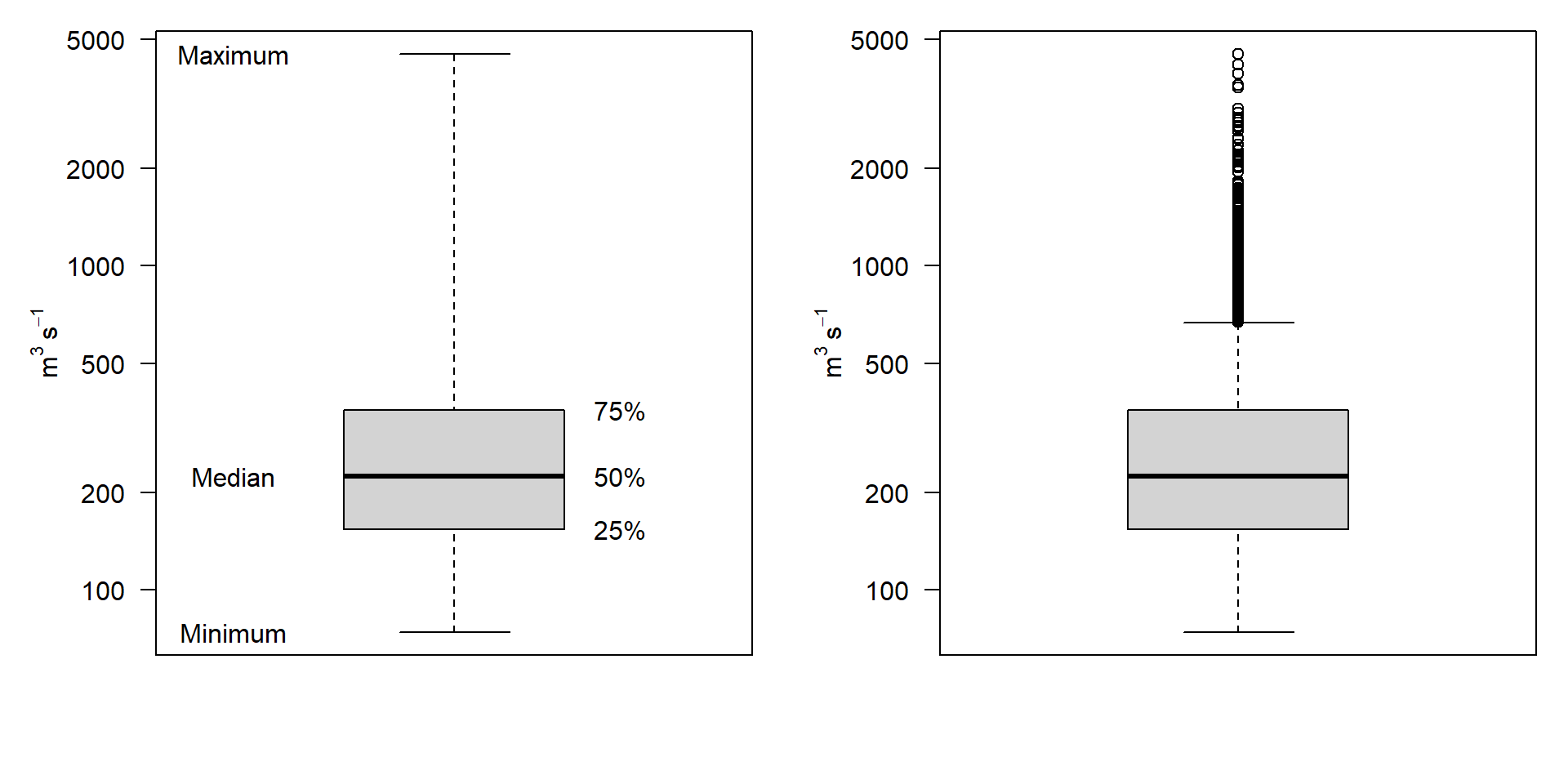
- Beachte die logarithmische Skala von y!
- In der rechten Version reichen die Whisker bis zum einem Datenpunkt, der nicht weiter als das 1,5-fache des Interquartilabstandes der Box entfernt ist.
Beispiel: Vergleich zweier Mittelwerte
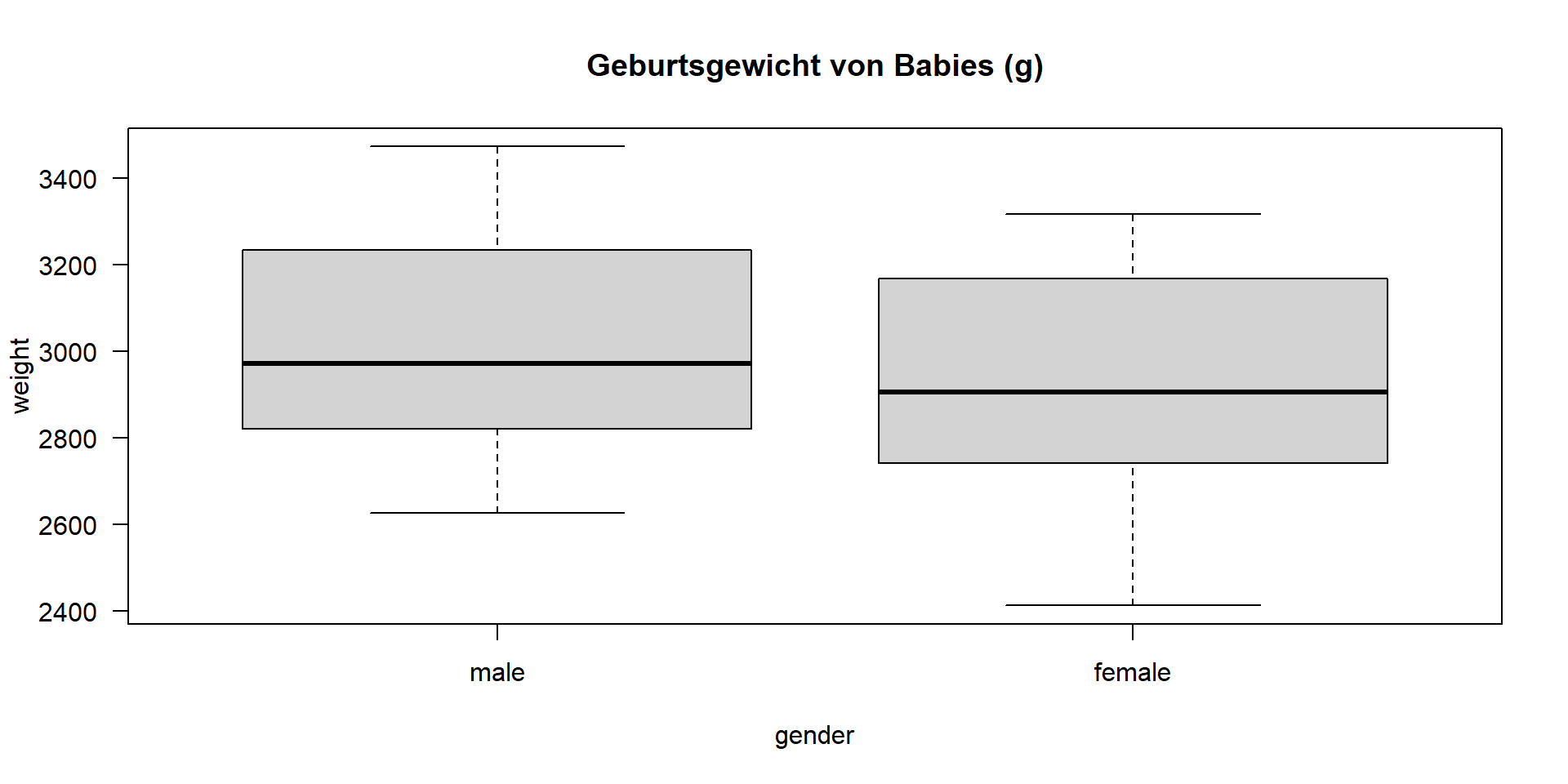
- Ein gegebener Datensatz (Dobson, 1983) enthält das Geburtsgewicht (in g) von 12 Jungen und 12 Mädchen.
- Hat der Unterschied etwas mit dem Geschlecht der Babys zu tun oder handelt es sich um Zufall?
Datenverarbeitung
Benötigte Software
- Ein Tabellenkalkulationsprogramm, Excel oder LibreOffice https://www.libreoffice.org/
- Das R-System für Datenanalyse und Grafiken https://www.r-project.org
- RStudio zum benutzerfreundlichen Arbeiten mit R https://posit.co/download/rstudio-desktop/
Warum R?
- “lingua franca of computational statistics”.
- Äußerst leistungsfähig
- Kein anderes System verfügt über so viele statistische Methoden
- Wird in der statistischen Forschung verwendet
- Frei (OpenSource)
- Frei zu benutzen
- Frei zu modifizieren
- Frei, etwas beizutragen
- Weniger kompliziert als man denkt:
- Ja, man braucht Kommandozeilenprogrammierung
- aber: schon eine einzige Zeile kann viel bewirken
- große Anzahl Bücher und Online-Skripte
Im Gegensatz zu anderen Systemen ist Copy & Paste erlaubt – aber bitte zitieren.