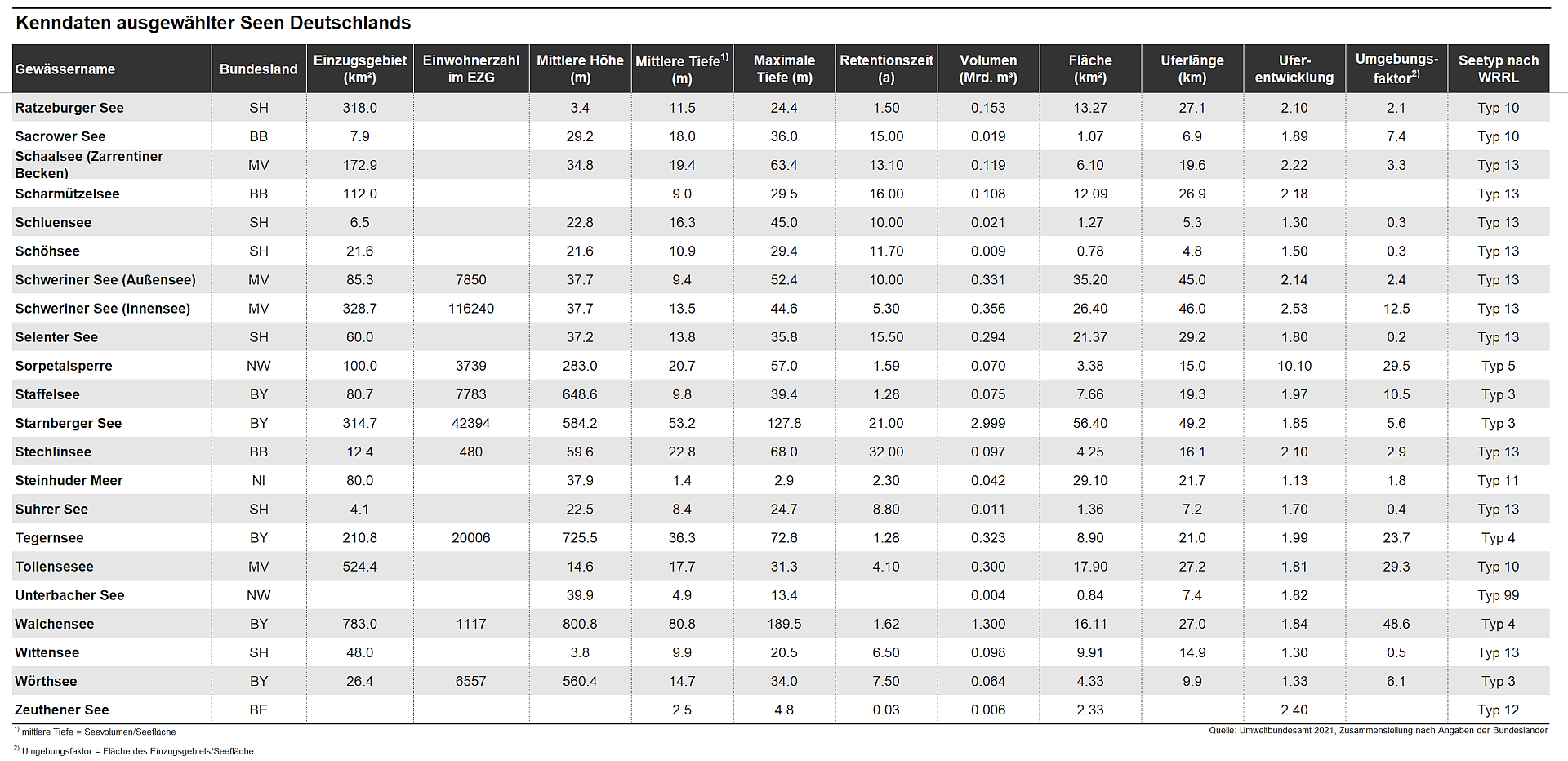
Example: A simplified subset from the UBA lake data
name
shortname
z_mean
z_max
t_ret
volume
area
p_tot
n_no3
chl
wfd_type
Ammer
Ammersee
Ammer
37.60
81.1
2.70
1.75000
46.600
7.3
1.09
2.80
Typ 4
Arend
Arendsee
Arend
28.60
48.7
50.00
0.14700
5.140
375.0
0.05
22.30
Typ 13
Boden
Bodensee
Boden
85.00
254.0
4.20
48.52150
571.500
6.9
0.84
2.10
Typ 4
Chiem
Chiemsee
Chiem
25.60
73.4
1.26
2.04800
79.900
9.2
0.55
3.80
Typ 4
Dober
Dobersdorfer See
Dober
5.40
18.8
2.30
0.01690
3.120
63.9
0.64
27.30
Typ 14
Muegg
Großer Müggelsee
Muegg
4.85
7.5
0.20
0.03500
7.200
189.9
0.17
32.90
Typ 11
Ploen
Großer Plöner See
Ploen
12.40
58.0
3.10
0.37200
29.970
62.3
0.22
8.80
Typ 13
Kumme
Kummerower See
Kumme
8.10
23.3
1.50
0.26300
32.500
65.3
0.78
16.60
Typ 11
Mueritz
Müritz (Außenmüritz)
Mueritz
6.50
28.1
6.00
0.68000
105.300
19.7
0.11
6.30
Typ 14
MuerB
Müritz (Binnenmüritz)
MuerB
9.80
30.3
6.00
0.03800
3.910
34.2
0.11
6.70
Typ 10
Plaue
Plauer See
Plaue
6.80
25.5
3.00
0.30000
38.400
26.0
0.09
6.80
Typ 10
Sacro
Sacrower See
Sacro
18.01
36.0
15.00
0.01930
1.072
79.8
0.04
8.60
Typ 10
Schar
Scharmützelsee
Schar
9.00
29.5
16.00
0.10823
12.090
35.3
0.12
10.40
Typ 13
SchwA
Schweriner See (Außensee)
SchwA
9.40
52.4
10.00
0.33100
35.200
100.0
0.23
11.70
Typ 13
SchwI
Schweriner See (Innensee)
SchwI
13.50
44.6
5.30
0.35600
26.400
246.5
0.19
5.86
Typ 13
Starn
Starnberger See
Starn
53.20
127.8
21.00
2.99900
56.400
5.9
0.32
1.84
Typ 3
Stech
Stechlinsee
Stech
22.80
68.0
32.00
0.09700
4.250
15.8
0.04
2.60
Typ 13
Stein
Steinhuder Meer
Stein
1.35
2.9
2.30
0.04200
29.100
53.3
0.12
29.00
Typ 11
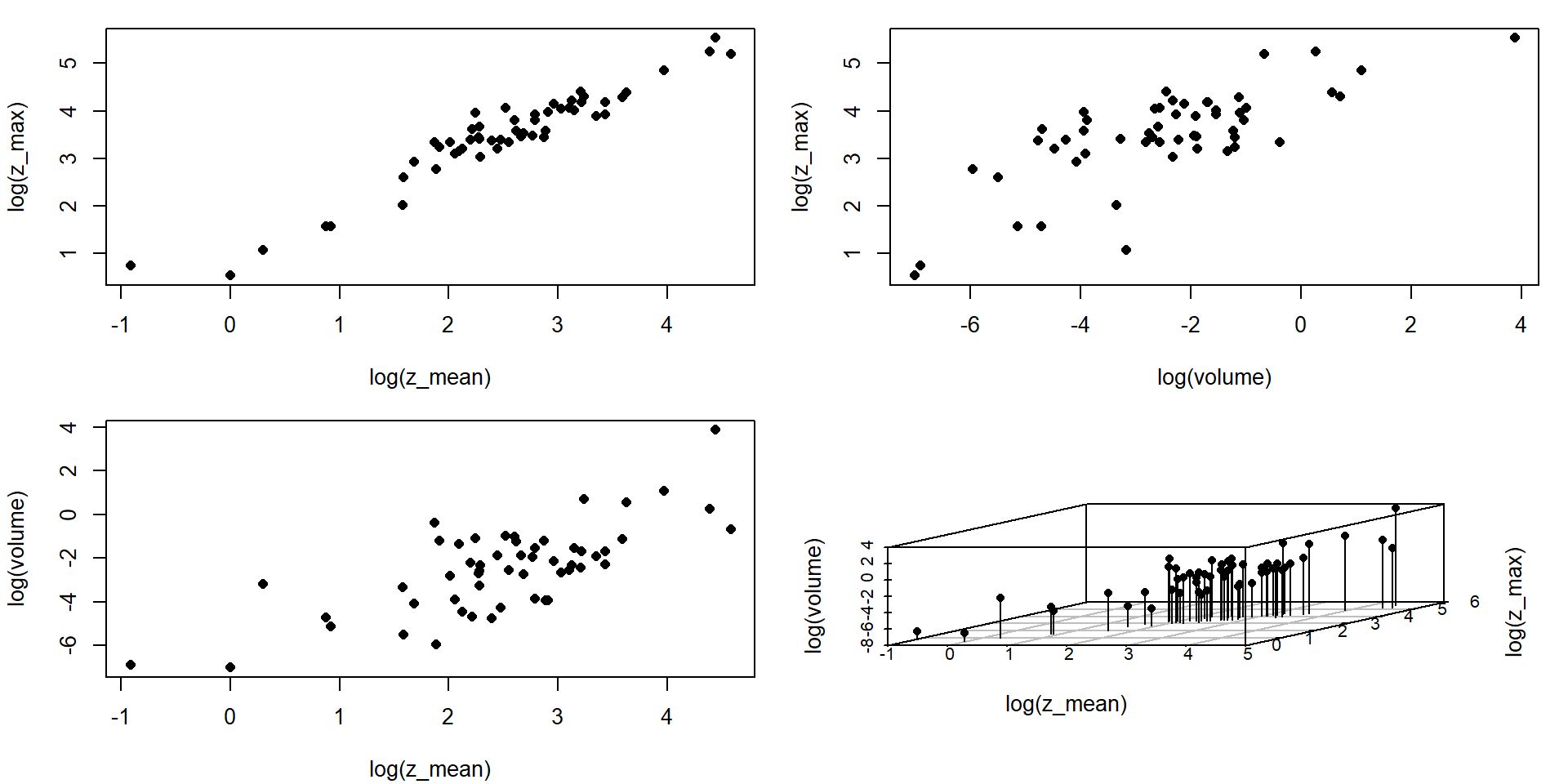
mean and maximum depth (\(\mathrm{m}\)): z_mean, z_max; retention time (years): t_ret; volume (\(\mathrm{10^9 m^3}\)); area (\(\mathrm{km^2}\)), total phosphorus P (\(\mathrm{\mu g/L}\)): p_tot; nitrogen-N (\(\mathrm{mg/L}\)): n_no3, chlorophyll (\(\mathrm{\mu g/L}\)): chl, water framework directive lake type: wfd_type
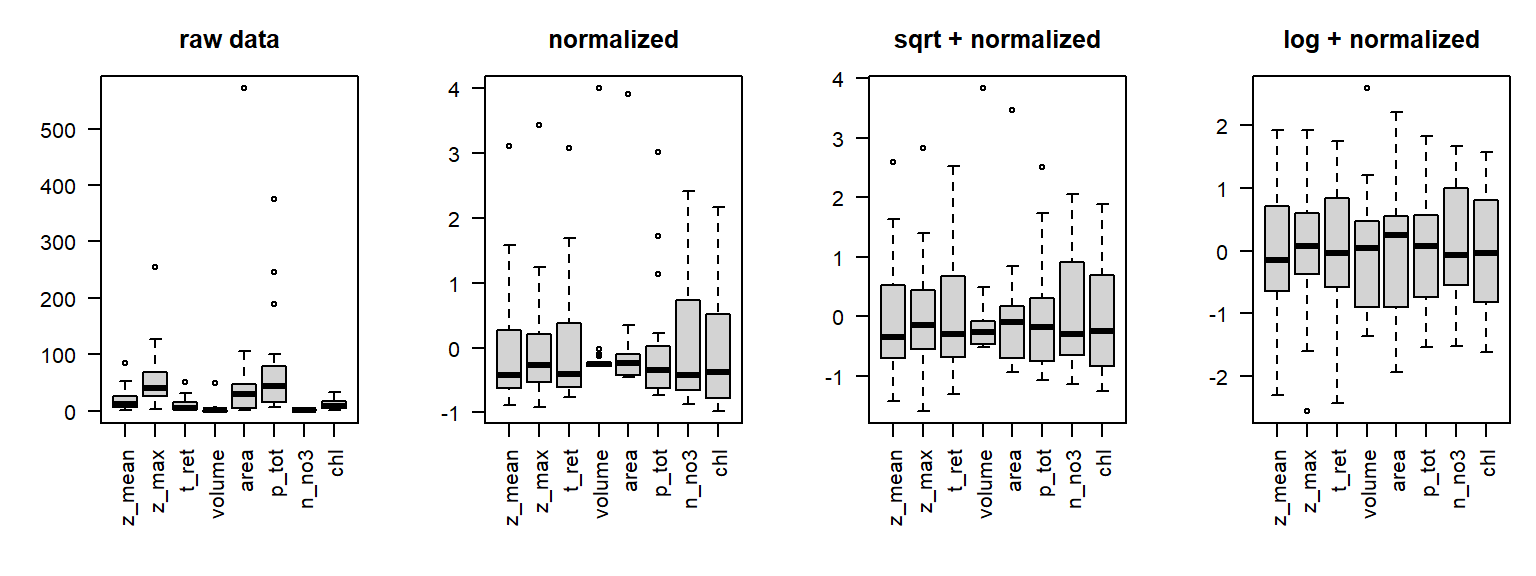
par(mfrow =c(1, 4), mar =c(6, 4, 3, 1), las =2)boxplot(lakedata, main ="raw data")boxplot(scale(lakedata), main ="normalized")boxplot(scale(sqrt(lakedata)), main ="sqrt + normalized")boxplot(scale(log(lakedata)), main ="log + normalized")
scale() performs normalisation (z-transformation)
aim: make different scales better comparable
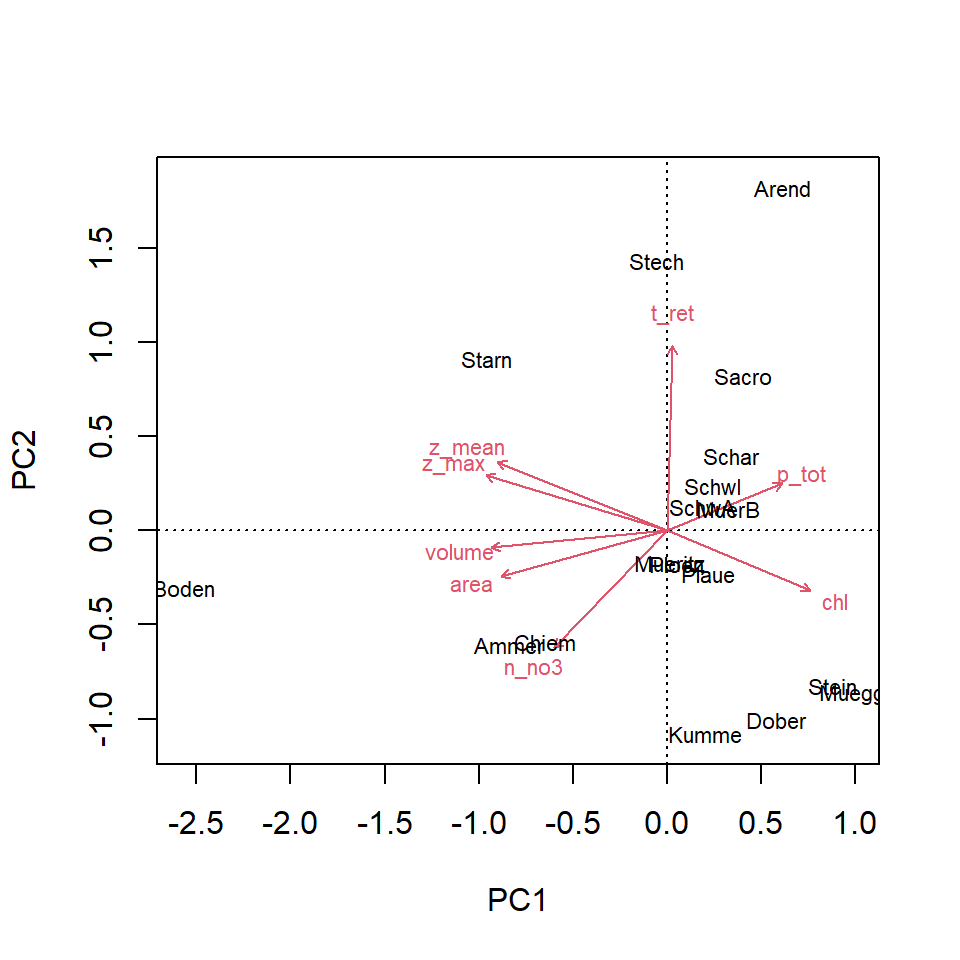
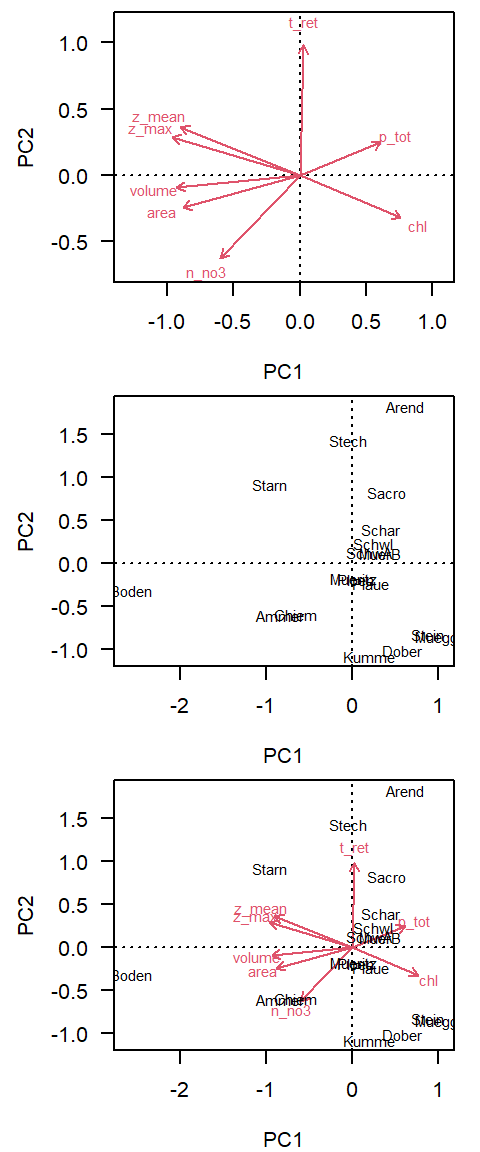
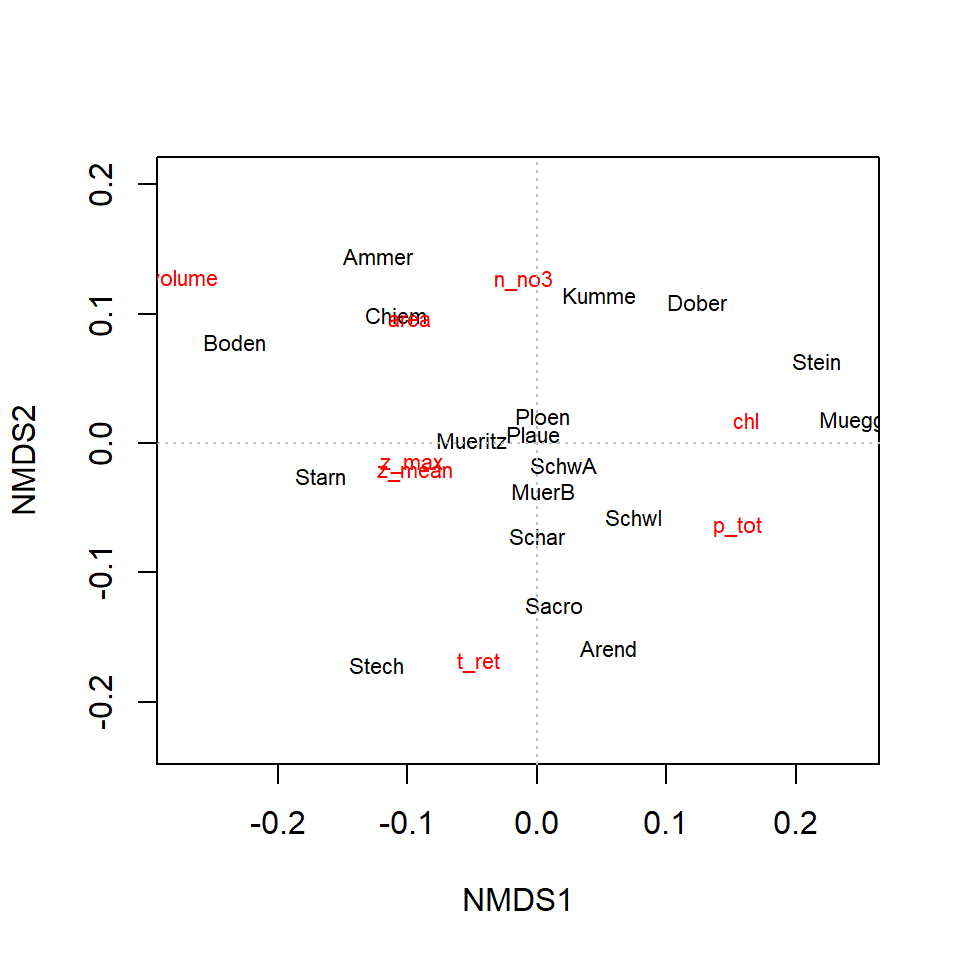
Ordination methods
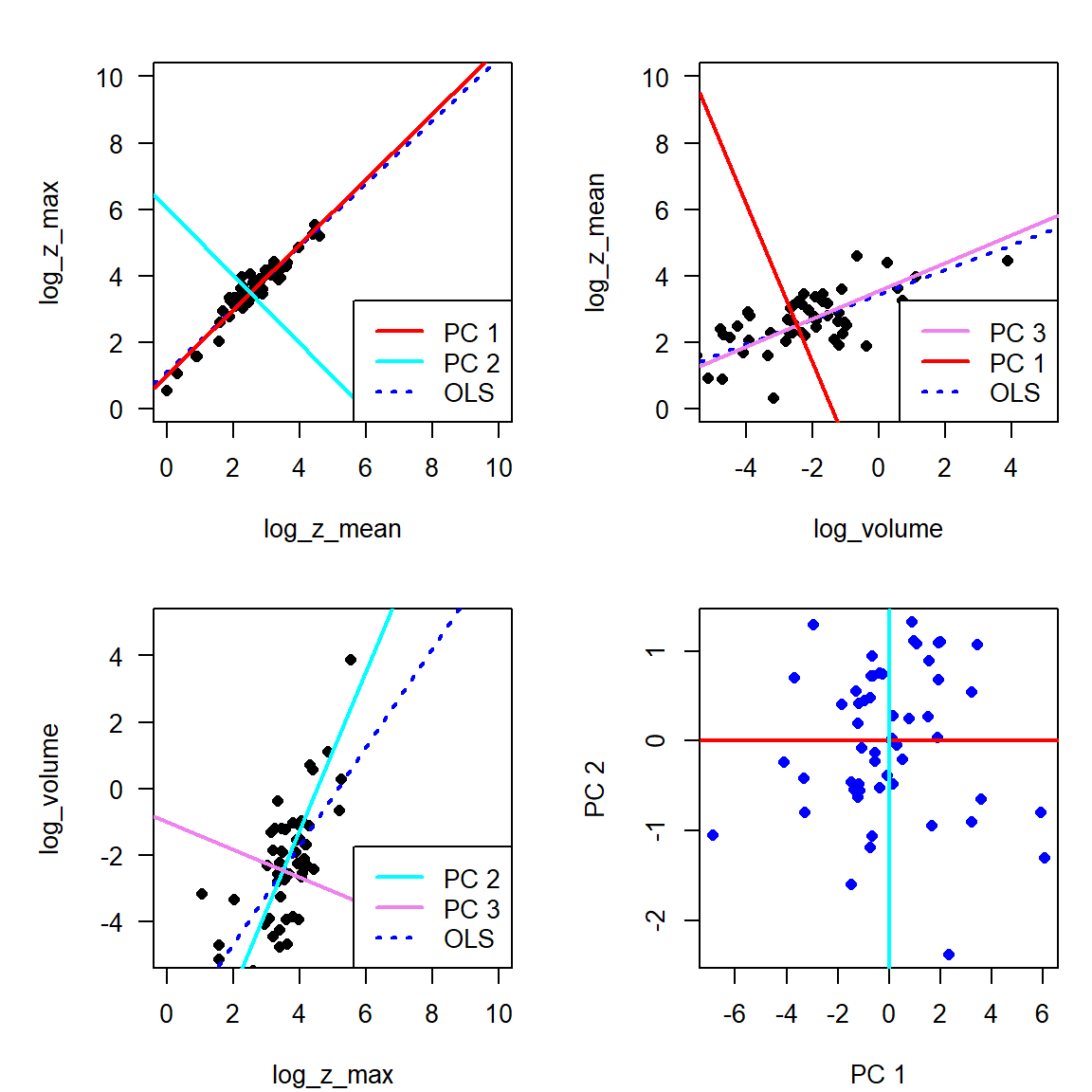
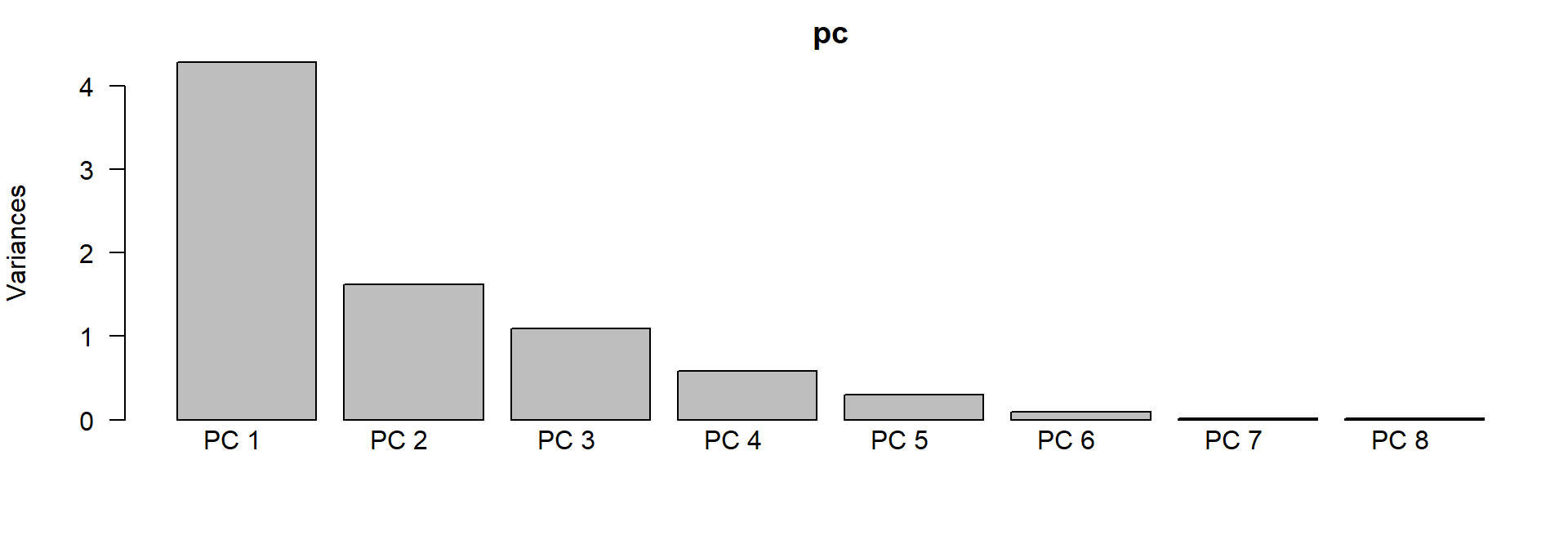
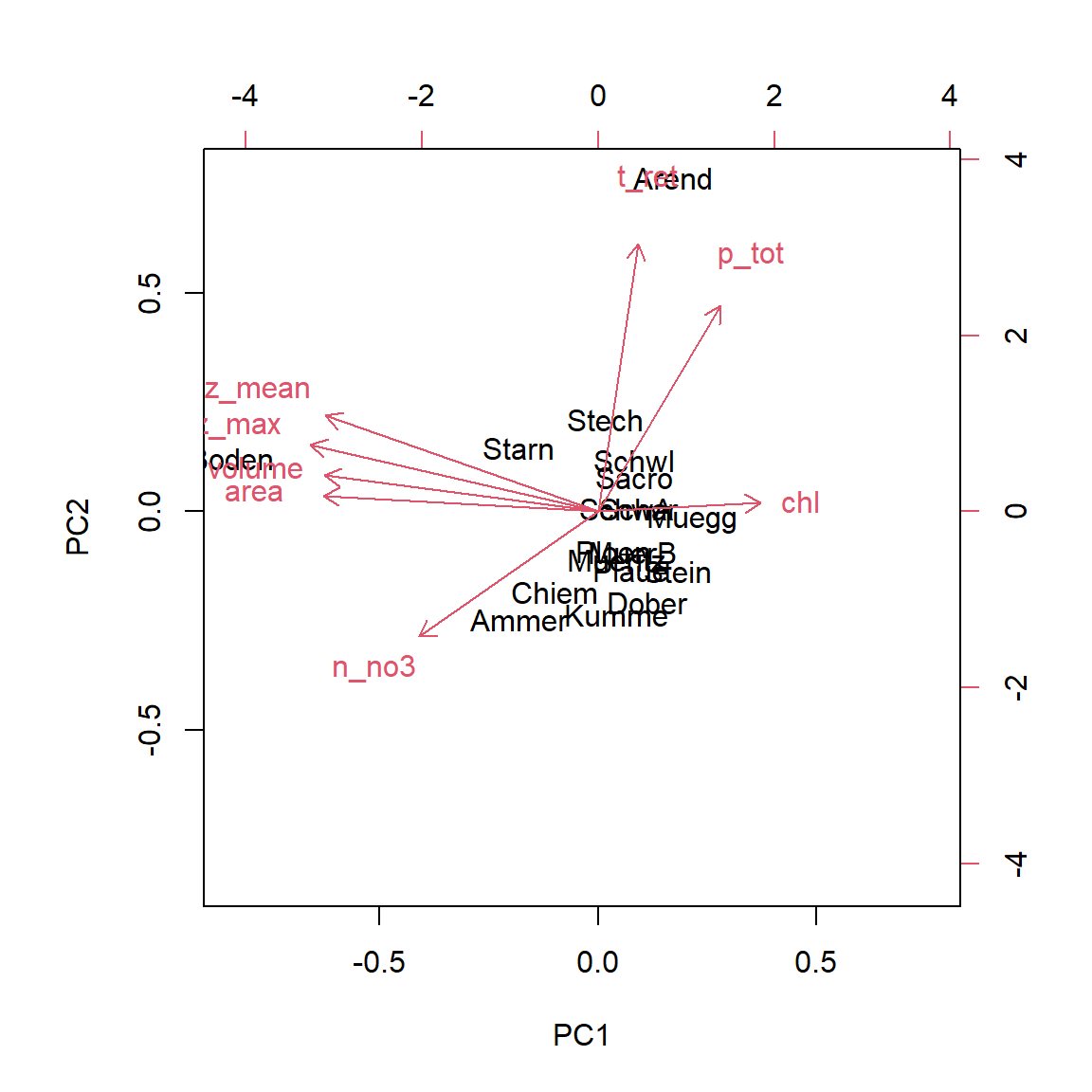
Principal Component Analysis: PCA
identify cvovariance or correlation structure
rotate coordinate system, so that it points in the diretions of maximum variance
\(k\) dimensions in original space are transformed into \(k\) orthogonal (rectangular) coordinates in principal components space.