| treat | replicate 1 | replicate 2 | replicate 3 |
|---|---|---|---|
| Fertilizer | 0.020 | -0.217 | -0.273 |
| F. open | 0.940 | 0.780 | 0.555 |
| F.+sugar | 0.188 | -0.100 | 0.020 |
| F.+CaCO3 | 0.245 | 0.236 | 0.456 |
| Bas.med. | 0.699 | 0.727 | 0.656 |
| A.dest | -0.010 | 0.000 | -0.010 |
| Tap water | 0.030 | -0.070 | NA |
07-One and two-way ANOVA
Applied Statistics – A Practical Course
2026-01-28
A practical example
Find a suitable medium for growth experiments with green algae
- cheap, easy to handle
- suitable for students courses and classroom experiments

Idea
- use a commercial fertilizer with the main nutrients N and P
- mineral water with trace elements
- does non-sparkling mineral water contain enough \(\mathrm{CO_2}\)?
- test how to improve \(\mathrm{CO_2}\) availability for photosynthesis
Experimental design

- each treatment with 3 replicates
- randomized placement on a shaker
- 16:8 light:dark-cycle
- measurement directly in the bottles using a self-made turbidity meter
Results
 Fertilizer – Open Bottle – F. + Sugar – F. + CaCO3 – Basal medium – A. dest – Tap water
Fertilizer – Open Bottle – F. + Sugar – F. + CaCO3 – Basal medium – A. dest – Tap water
Boxplot
boxplot(growth ~ treat, data = algae)
abline(h = 0, lty = "dashed", col = "grey")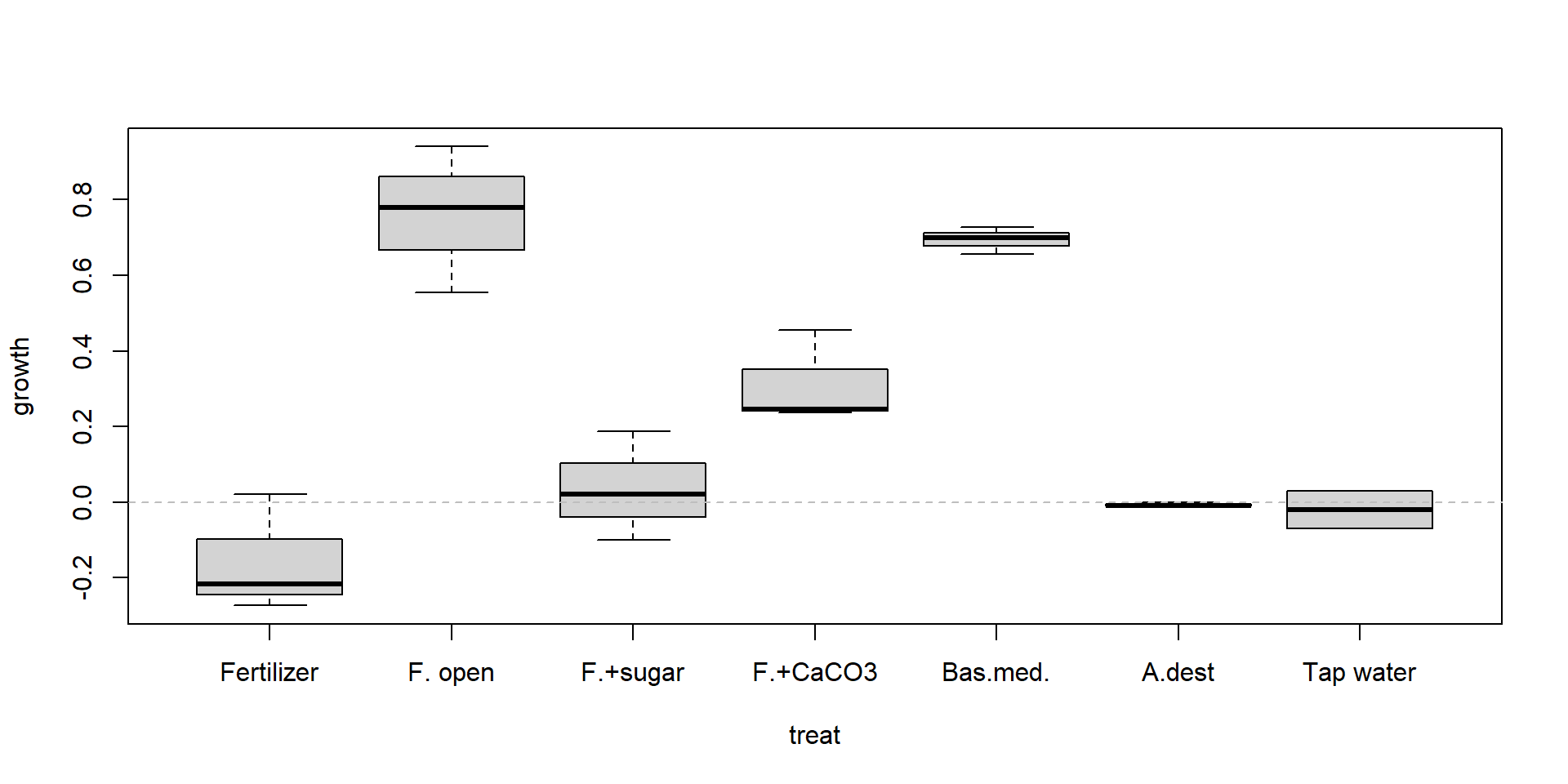
Stripchart
stripchart(growth ~ treat, data = algae, vertical = TRUE)
Better, because we have only 2-3 replicates. Boxplot needs more.
Then we fit a linear regression:
plot(weight ~ code, data = clem, axes = FALSE)
m <- lm(weight ~ code, data = clem)
axis(1, at = c(1,2), labels = c("EB", "EP")); axis(2); box()
abline(m, col = "blue")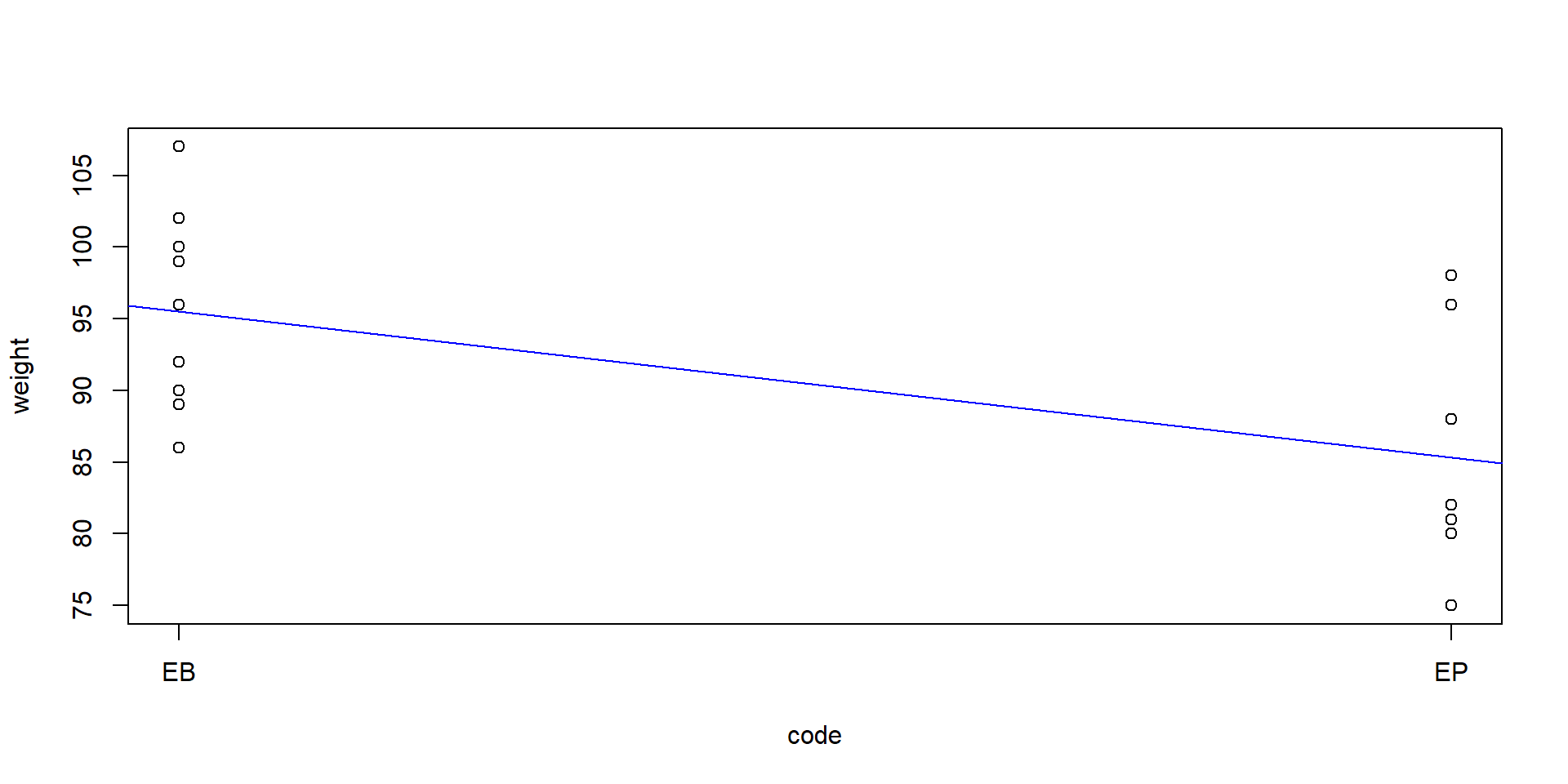
Graphical output
par(las = 1) # las = 1 make y annotation horizontal
par(mar = c(4, 10, 3, 1)) # more space at the left for axis annotation
plot(tk)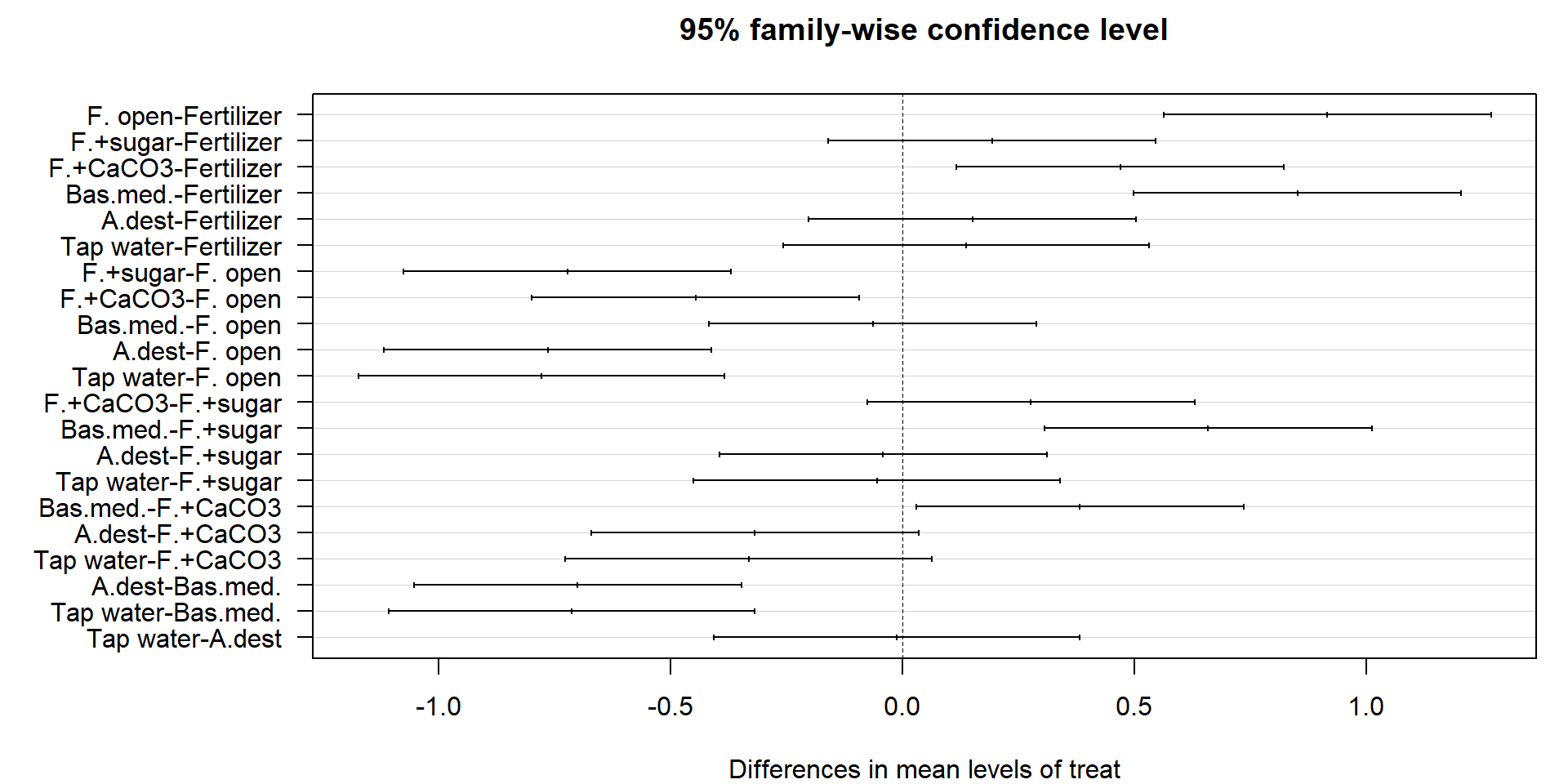
ANOVA assumptions and diagnostics
ANOVA has same assumptions as the linear model.
- Independence of errors
- Variance homogeneity
- Approximate normality of errors
Graphical checks are preferred.
par(mfrow=c(2, 2))
plot(m)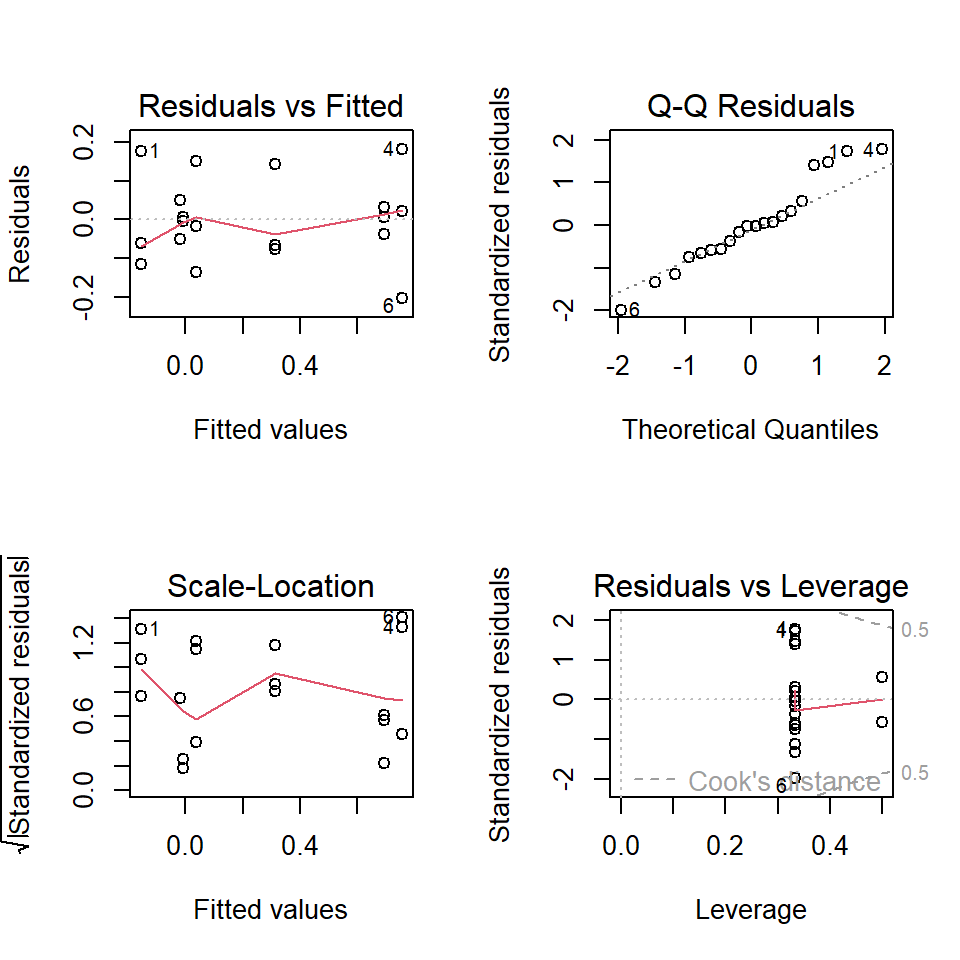
Numerical tests
Test variance homogeneity
- F-test compares only two variances.
- Several tests for multiple variances, e.g. Bartlett, Levene, Fligner-Killeen
- Recommended: Fligner-Killeen-test
fligner.test(growth ~ treat,
data = algae)
Fligner-Killeen test of homogeneity of variances
data: growth by treat
Fligner-Killeen:med chi-squared = 4.2095, df = 6, p-value = 0.6483Test of normal distribution
- The Shapiro-Wilks test can be misleading.
- Use a graphical method!
qqnorm(residuals(m))
qqline(residuals(m))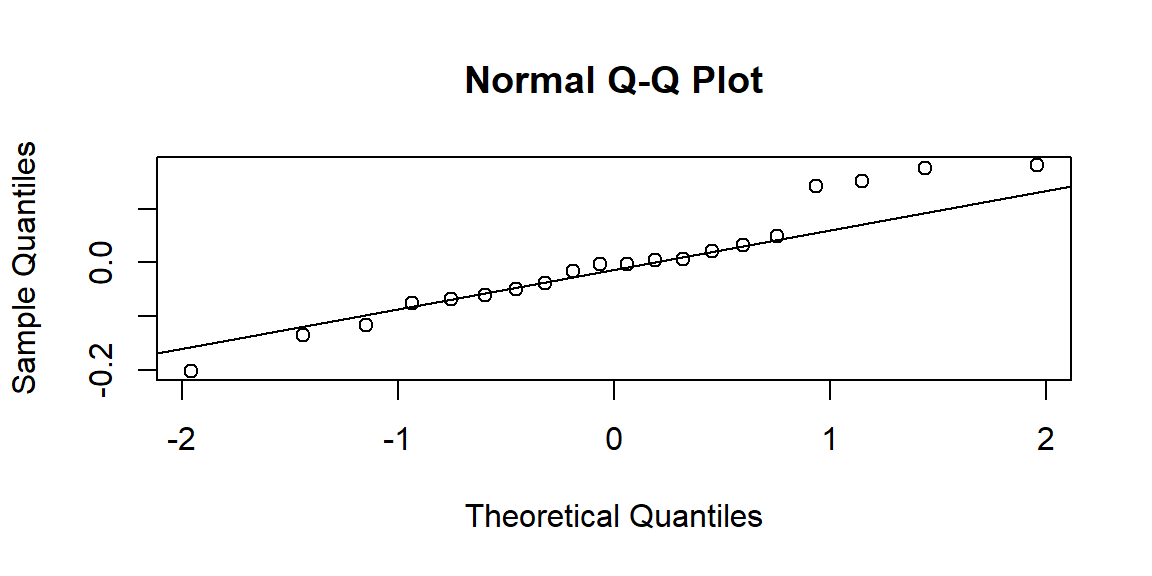
Linear model and ANOVA
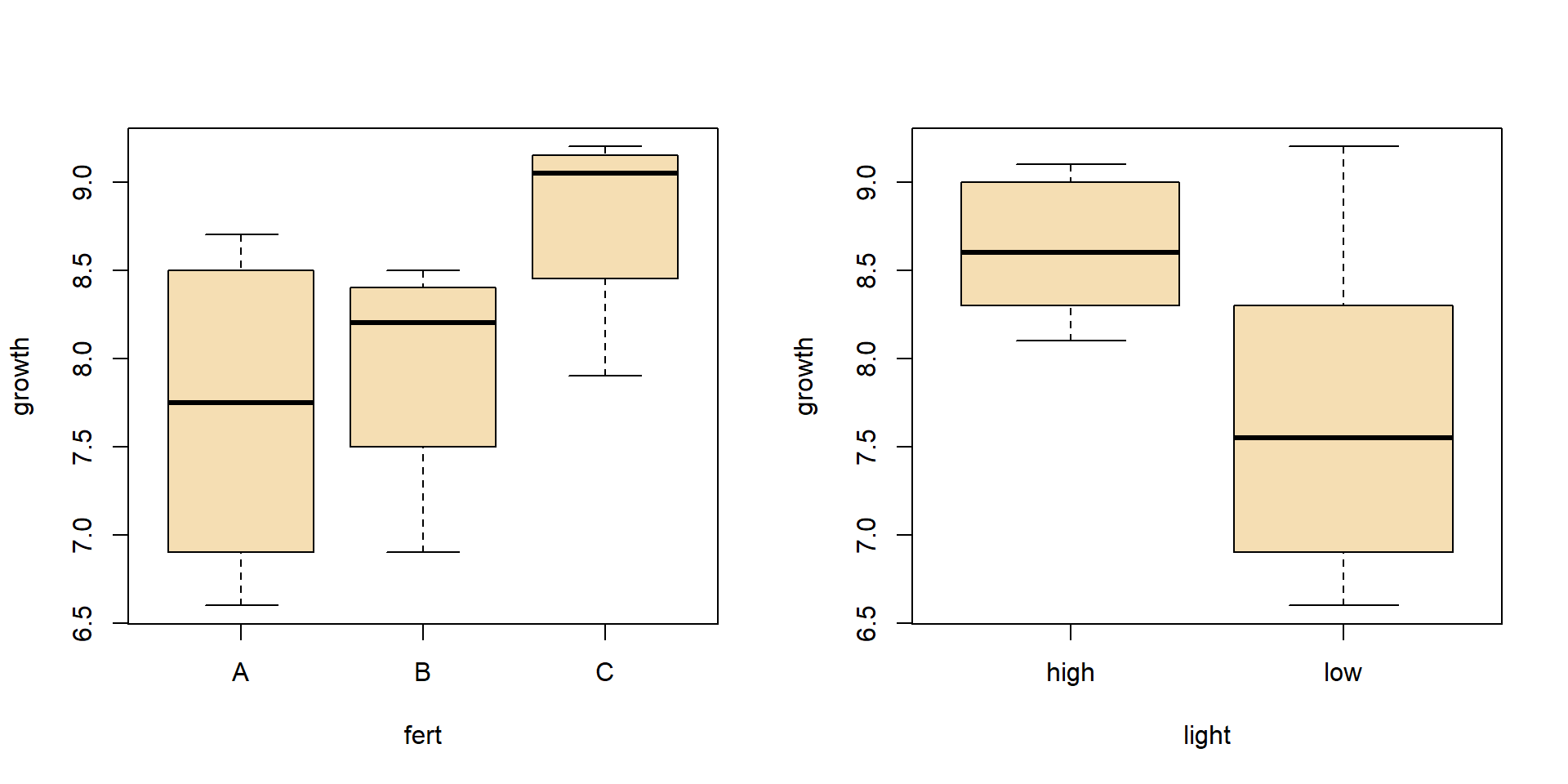
ANOVA
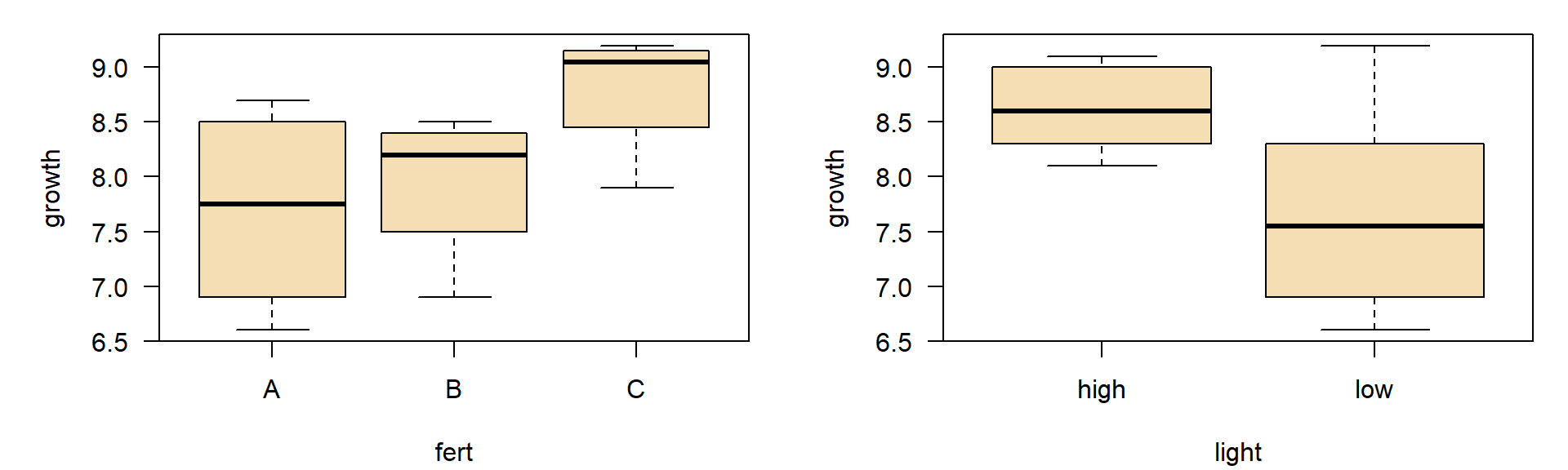
m <- lm(growth ~ light * fert, data = plants)
anova(m)Analysis of Variance Table
Response: growth
Df Sum Sq Mean Sq F value Pr(>F)
light 1 2.61333 2.61333 7.2258 0.03614 *
fert 2 2.66000 1.33000 3.6774 0.09069 .
light:fert 2 0.68667 0.34333 0.9493 0.43833
Residuals 6 2.17000 0.36167
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interaction plot
with(plants, interaction.plot(fert, light, growth,
col = c("orange", "brown"), lty = 1, lwd = 2))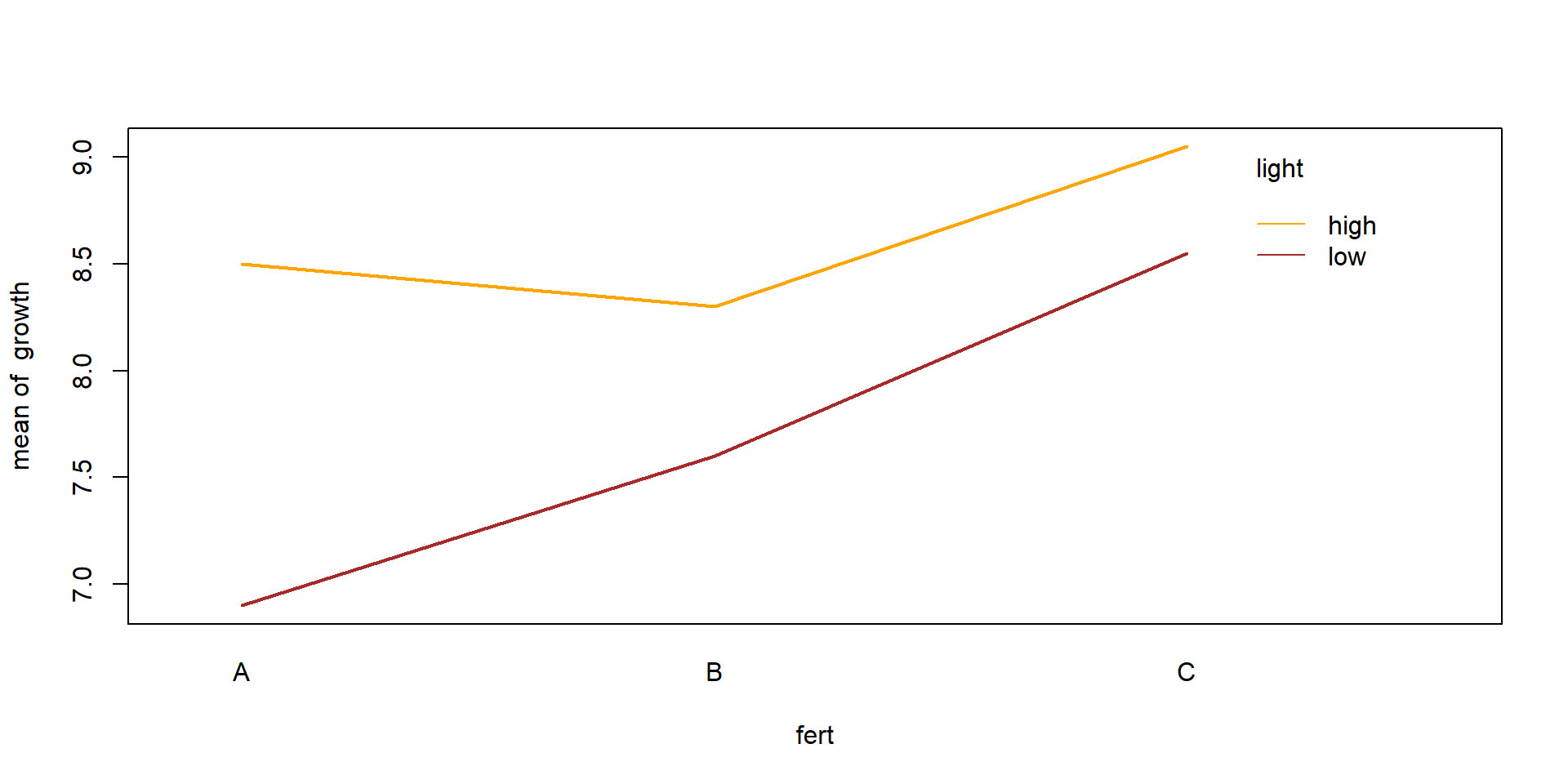
Diagnostics II
par(mfrow=c(1, 2))
par(cex=1.2, las=1)
qqnorm(residuals(m))
qqline(residuals(m))
plot(residuals(m)~fitted(m))
abline(h=0)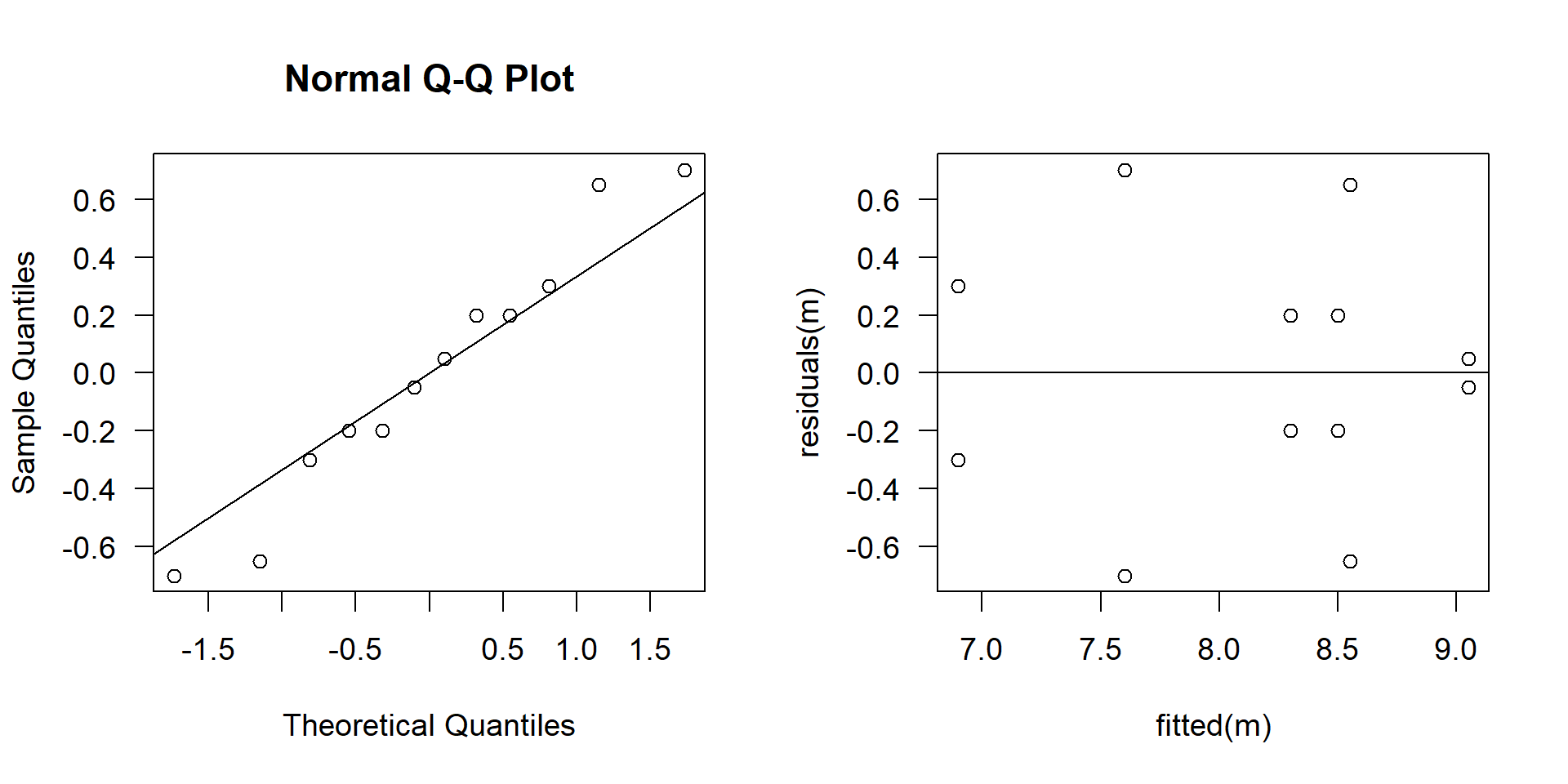
fligner.test(growth ~ interaction(light, fert), data=plants)
Fligner-Killeen test of homogeneity of variances
data: growth by interaction(light, fert)
Fligner-Killeen:med chi-squared = 10.788, df = 5, p-value = 0.05575Residuals: look ok and p-value of the Fligner test \(> 0.05\), \(\rightarrow\) looks fine.
Approach 1: one-way ANOVA
par(mar=c(4, 8, 2, 1), las=1)
m <- lm(mu ~ treat, data=mcyst)
anova(m)Analysis of Variance Table
Response: mu
Df Sum Sq Mean Sq F value Pr(>F)
treat 2 0.00053293 2.6647e-04 8.775 0.004485 **
Residuals 12 0.00036440 3.0367e-05
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1plot(TukeyHSD(aov(m)))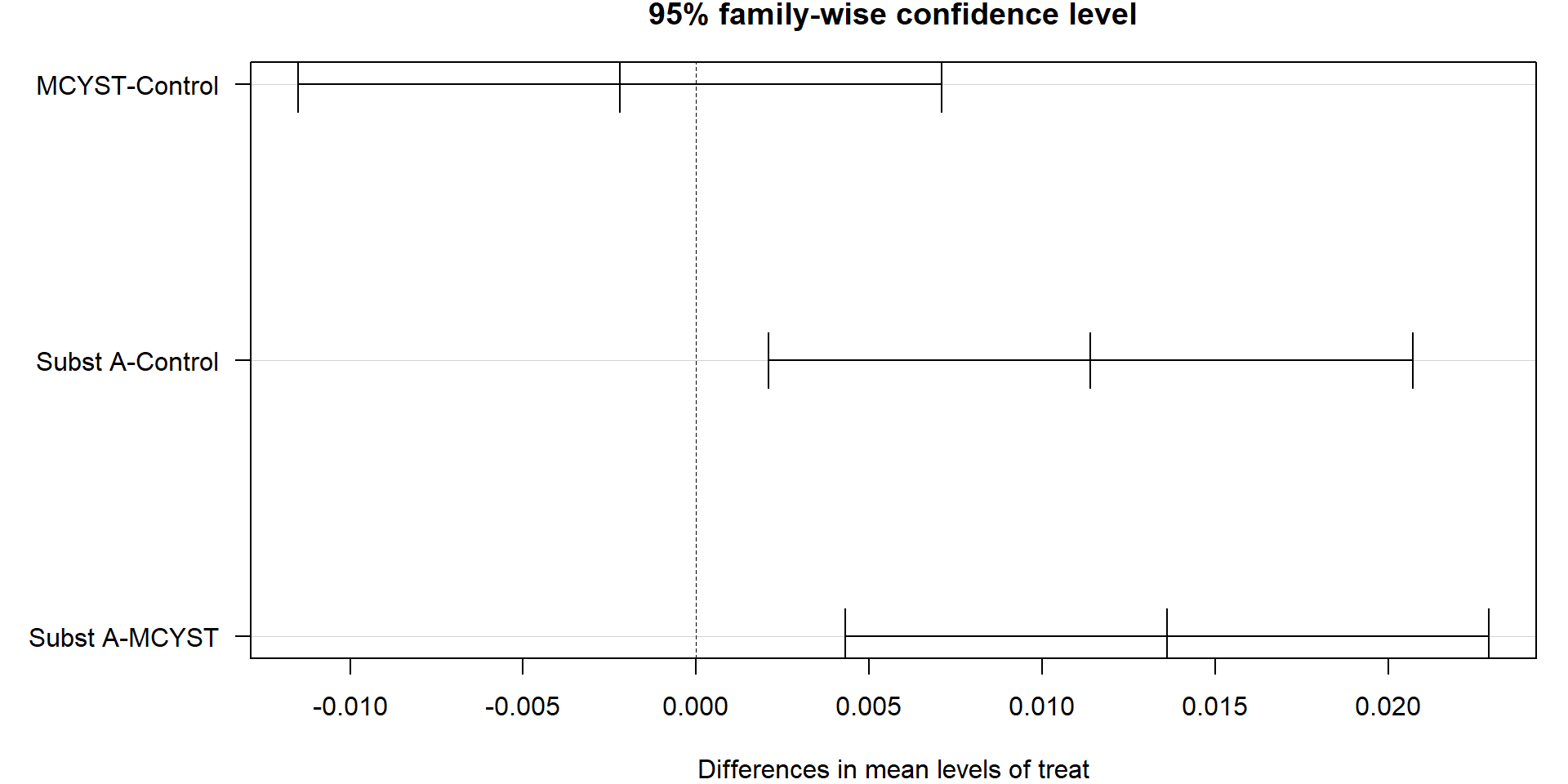
ANCOVA
Statistical question
- Comparison of regression lines
- Similar to ANOVA, but contains also metric variables (covariates)
Example
Annette Dobson’s birthweight data. A data set from a statistics textbook (Dobson, 2013), birth weight of boys and girls in dependence of the pregnancy week.
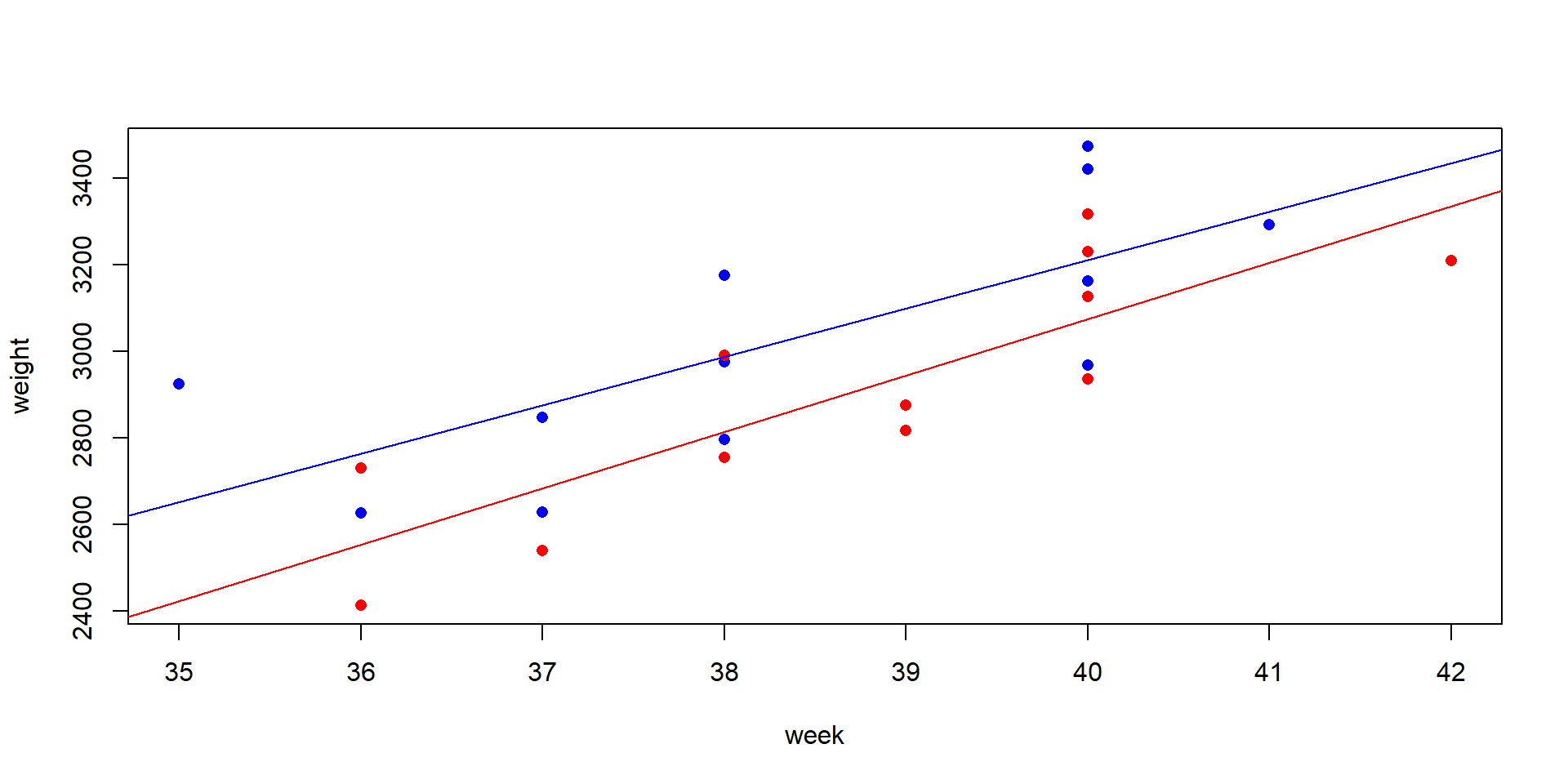
Anette Dobson’s birthweight data
Why not just using a t-test?
boxplot(weight ~ gender,data = dobson, ylab = "weight")t.test(weight ~ gender, data = dobson, var.equal = TRUE)
Two Sample t-test
data: weight by gender
t = 0.97747, df = 22, p-value = 0.339
alternative hypothesis: true difference in means between group M and group F is not equal to 0
95 percent confidence interval:
-126.3753 351.7086
sample estimates:
mean in group M mean in group F
3024.000 2911.333 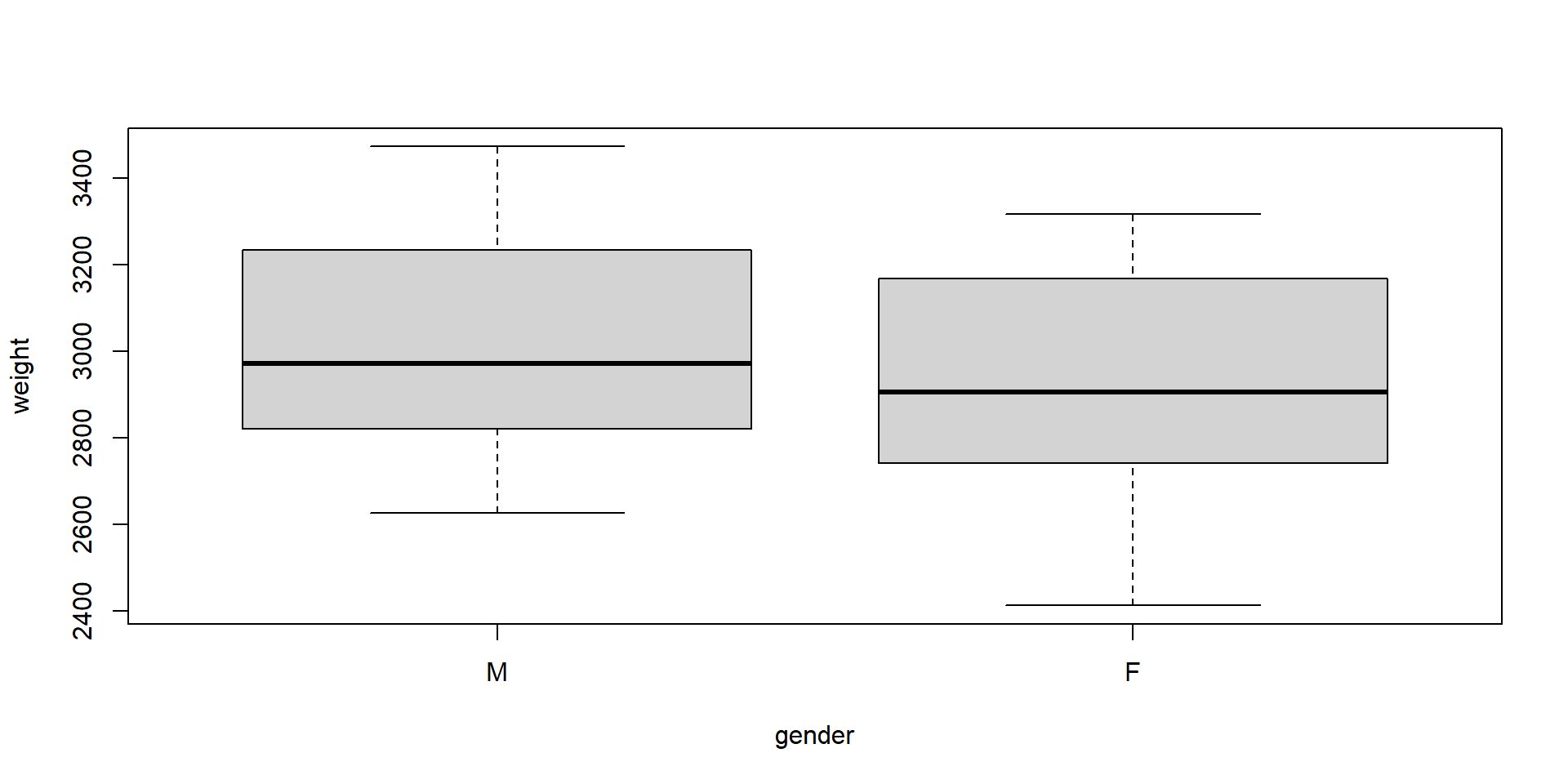
The box plot shows much overlap and the difference is not significant, because the t-test ignores important information: the pregnancy week.
ANCOVA makes use of covariates
m <- lm(weight ~ week * gender, data = dobson)
anova(m)Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
week 1 1013799 1013799 31.0779 1.862e-05 ***
gender 1 157304 157304 4.8221 0.04006 *
week:gender 1 6346 6346 0.1945 0.66389
Residuals 20 652425 32621
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1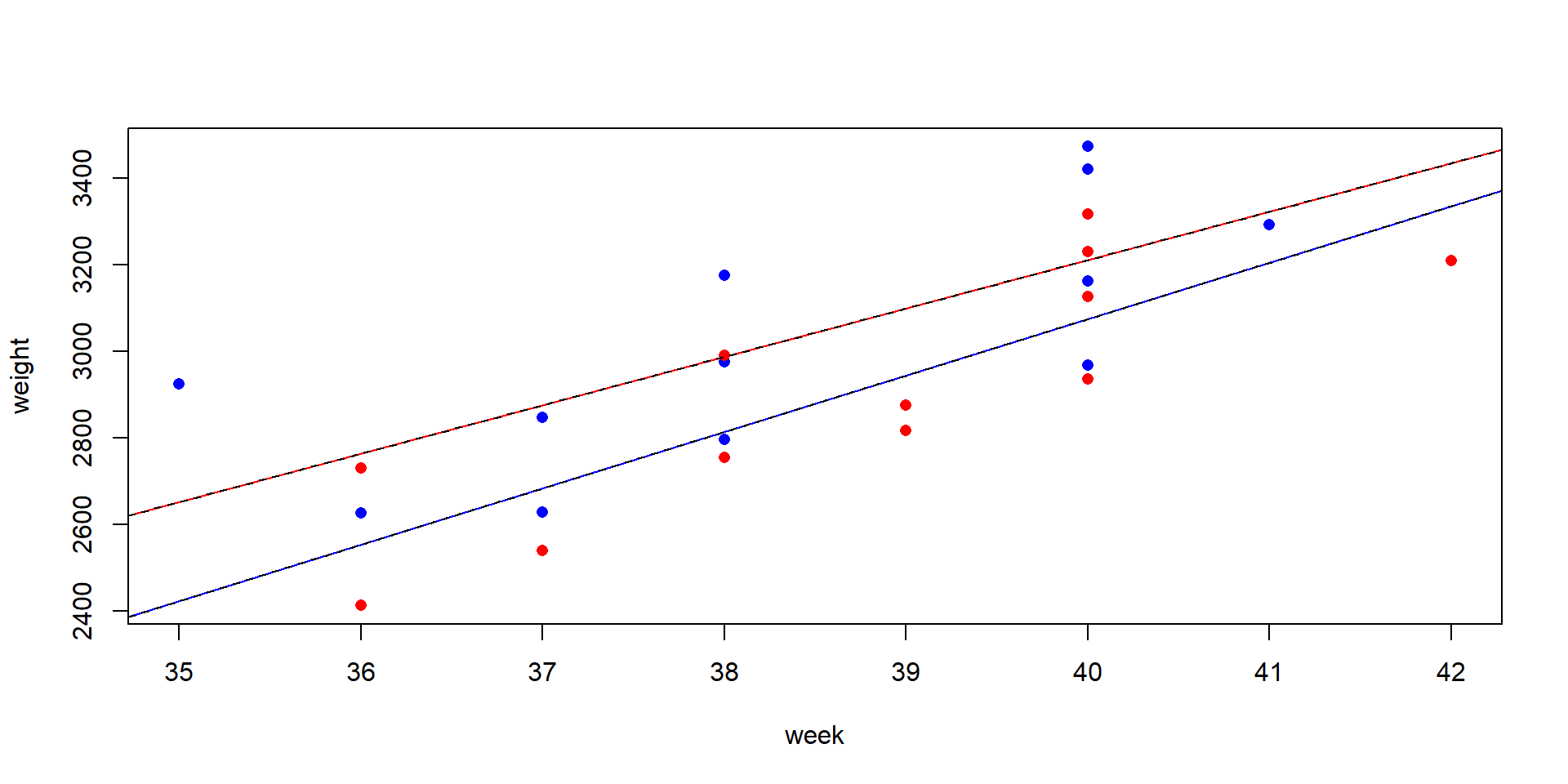
Type II ANOVA: Example
library("car")
m <- lm(growth ~ light * fert, data = plants)
Anova(m, type="II")Anova Table (Type II tests)
Response: growth
Sum Sq Df F value Pr(>F)
light 2.61333 1 7.2258 0.03614 *
fert 2.66000 2 3.6774 0.09069 .
light:fert 0.68667 2 0.9493 0.43833
Residuals 2.17000 6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1