df_vektor <- data.frame(
pH = c(5.0, 5.2, 5.5, 5.8, 6.0, 6.2, 6.5, 6.7, 7.0, 7.2),
# 1 = Gekeimt (Erfolg), 0 = Nicht Gekeimt (Misserfolg)
keimung = c(0, 0, 1, 1, 1, 1, 1, 0, 0, 0)
)
# Modellaufruf:
# glm(keimung ~ pH + I(pH^2), data = df_vektor, family = binomial)09-Generalized Linear Models
Angewandte Statistik – Ein Praxiskurs
2025-12-13
Anwendung: Toxizitätstest (Toxtest)
Ziel: Modellierung der Mortalität als Funktion der Dosis.
Datenstruktur (7 Dosisstufen): Verwendung des Matrix-Formats.
library(dplyr)
daphnia <- data.frame(
number = c(11, 13, 17, 10, 11, 10, 11),
dose = c(1, 2, 4, 8, 16, 32, 64),
dose_log = c(0, 1, 2, 3, 4, 5, 6), # zur Vereinfachung log_2 transformiert
survived = c(11, 12, 17, 6, 2, 0, 0)
)
plot(survived/(number) ~ dose, data = daphnia, pch=16)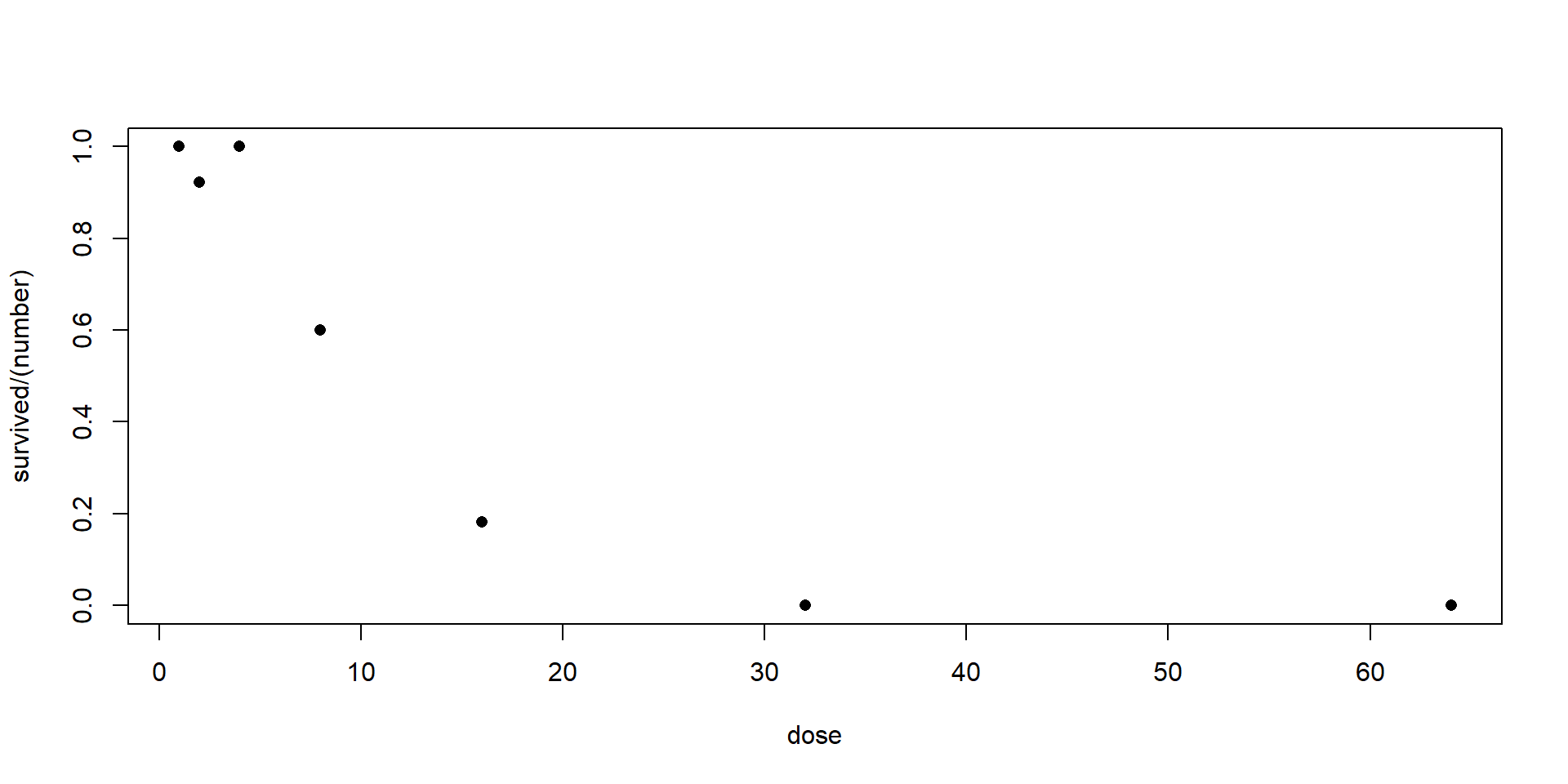
Konfidenzintervalle
Code
plot(daphnia$dose_log, daphnia$survived / daphnia$number,
pch = 16, col = "darkblue", ylim = c(0, 1), las=1,
xlab = "log2(Dose)", ylab = "Proportion Survived (p)")
lines(dose_seq$dose, dose_seq$prob, lwd = 2, col = "red")
lines(dose_seq$dose_log, dose_seq$upr, lty="dashed")
lines(dose_seq$dose_log, dose_seq$lwr, lty="dashed")
abline(h=0.5, lty="dotted")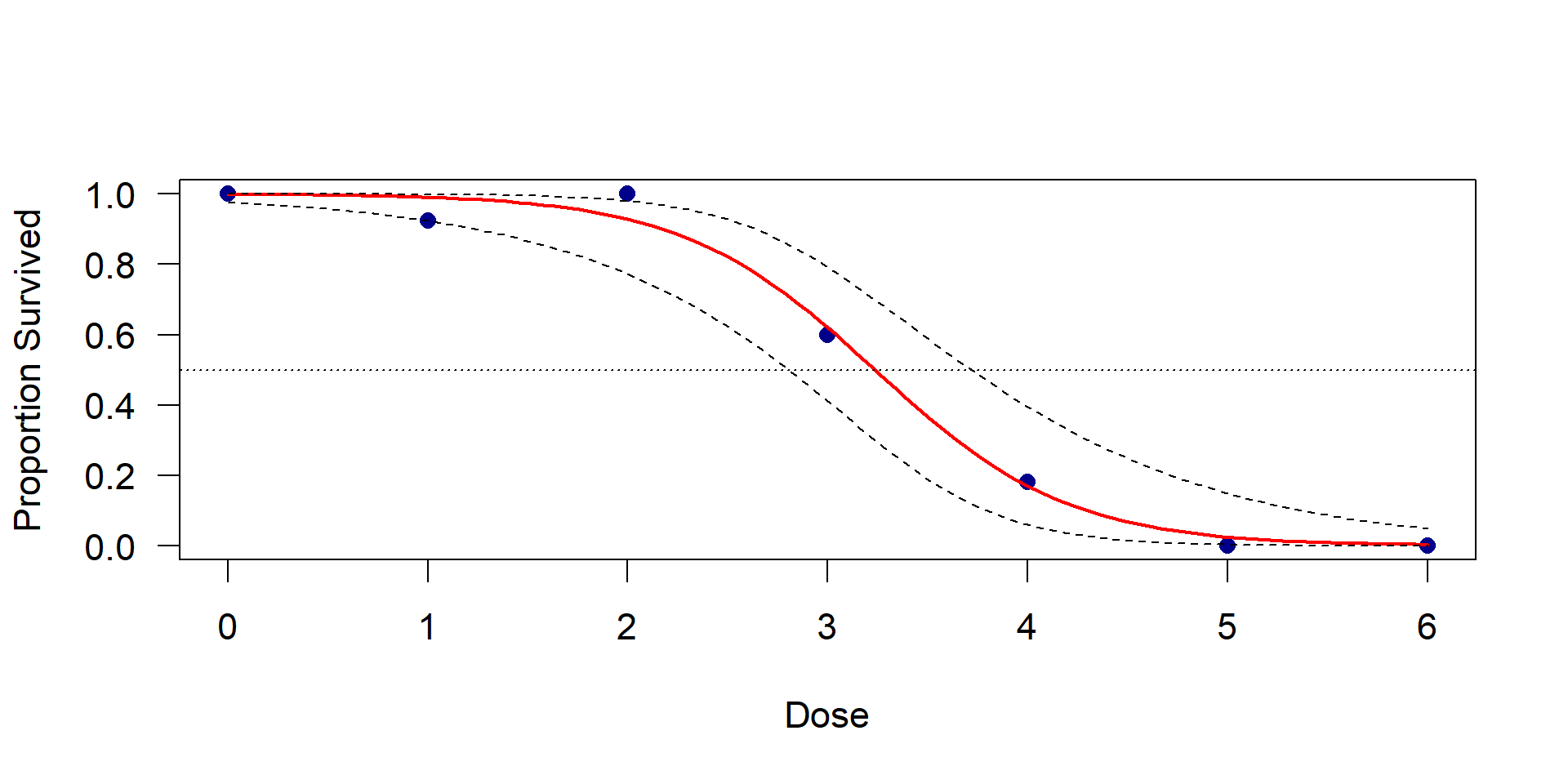
- Wir verwenden den \(z\)-Wert (
qnorm), da in GLMs die Normalverteilung der Koeffizienten (asymptotische Theorie) angenommen wird. plogis()ist die Umkehrfunktion des Logit-Links.- Rot: Die vom Modell geschätzte Überlebenswahrscheinlichkeit.
- Gestrichelt: Das 95%-Konfidenzintervall.
- Gepunktet (EC50): Schnittpunkt der Kurve mit \(\text{p}=0.5\). An diesem Punkt ist der lineare Prädiktor \(\eta\) genau Null.
Diagnostik-Plots
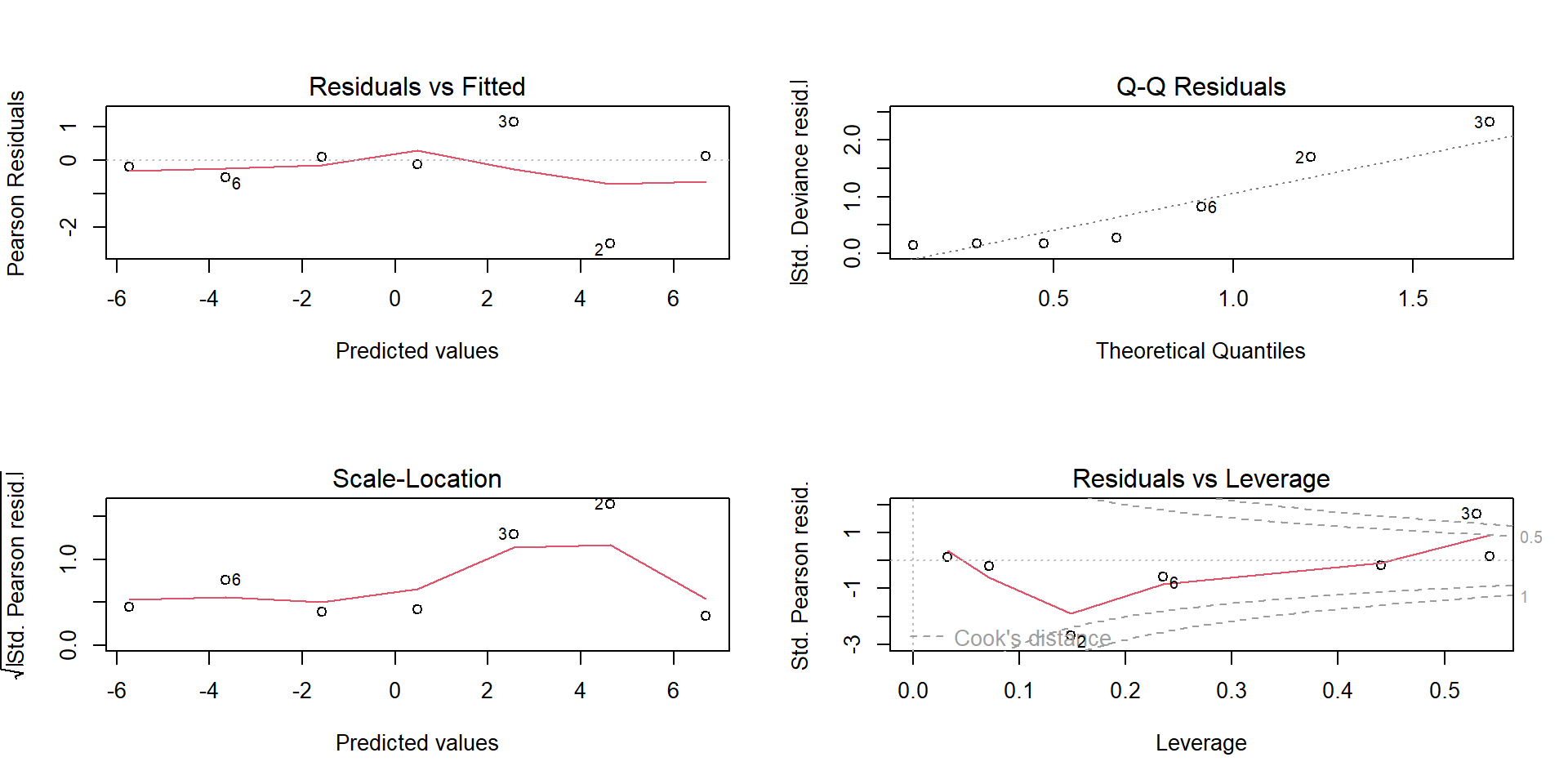
Plot und ED50 bzw. EC50
**drc*+ vereinfacht Visualisierung und Schätzung der EC50.
- Plot mit 95% CI
plot(m_drc, type = "all", xlab = "Log2-Dosis")- Schätzung der EC50 (ED50) mit CI
ED(m_drc, respLev = 50, interval = "delta")
Estimated effective doses
Estimate Std. Error Lower Upper
e:1:50 9.9953 1.3479 7.3536 12.6371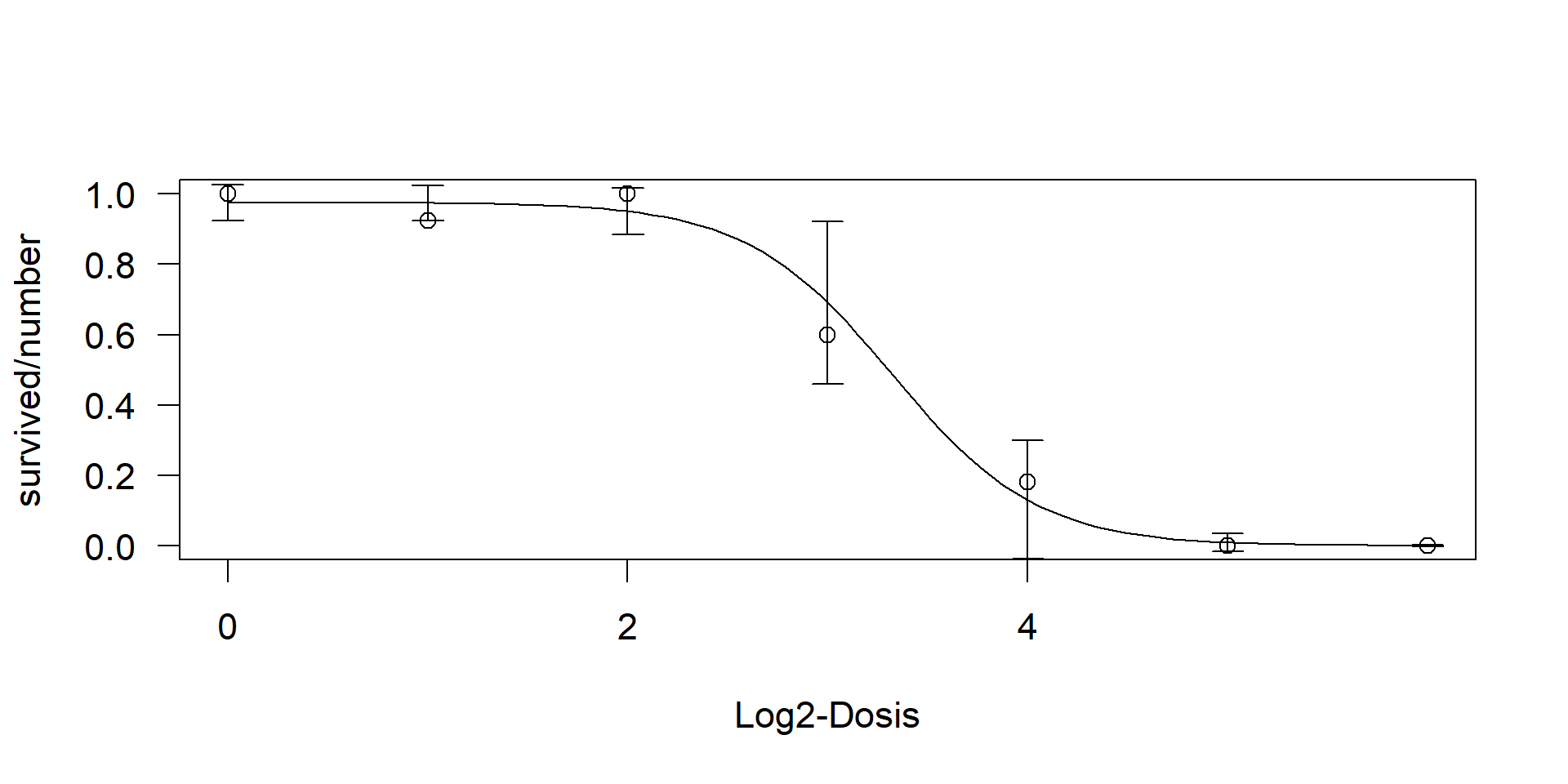
- Schätzung von EC50 und des CI ist mit drc direkter und robuster als mit
glm. - CI an den Rändern nur approximativ (überschreitet Intervall (0, 1))
Verwendete Pakete
Zur Visualisierung könnte man sich eine “base graphics” zusammenbauen oder ggplot2 verwenden.
Im folgenden verwenden wir das Paket tinyplot (McDermott et al., 2025) sowie Pakete aus der easystats-Familie (Lüdecke et al., 2021, 2022).
Ein Vorteil von tinyplot ist, dass man darin direkt Modellformeln verwenden kann.
Code anzeigen
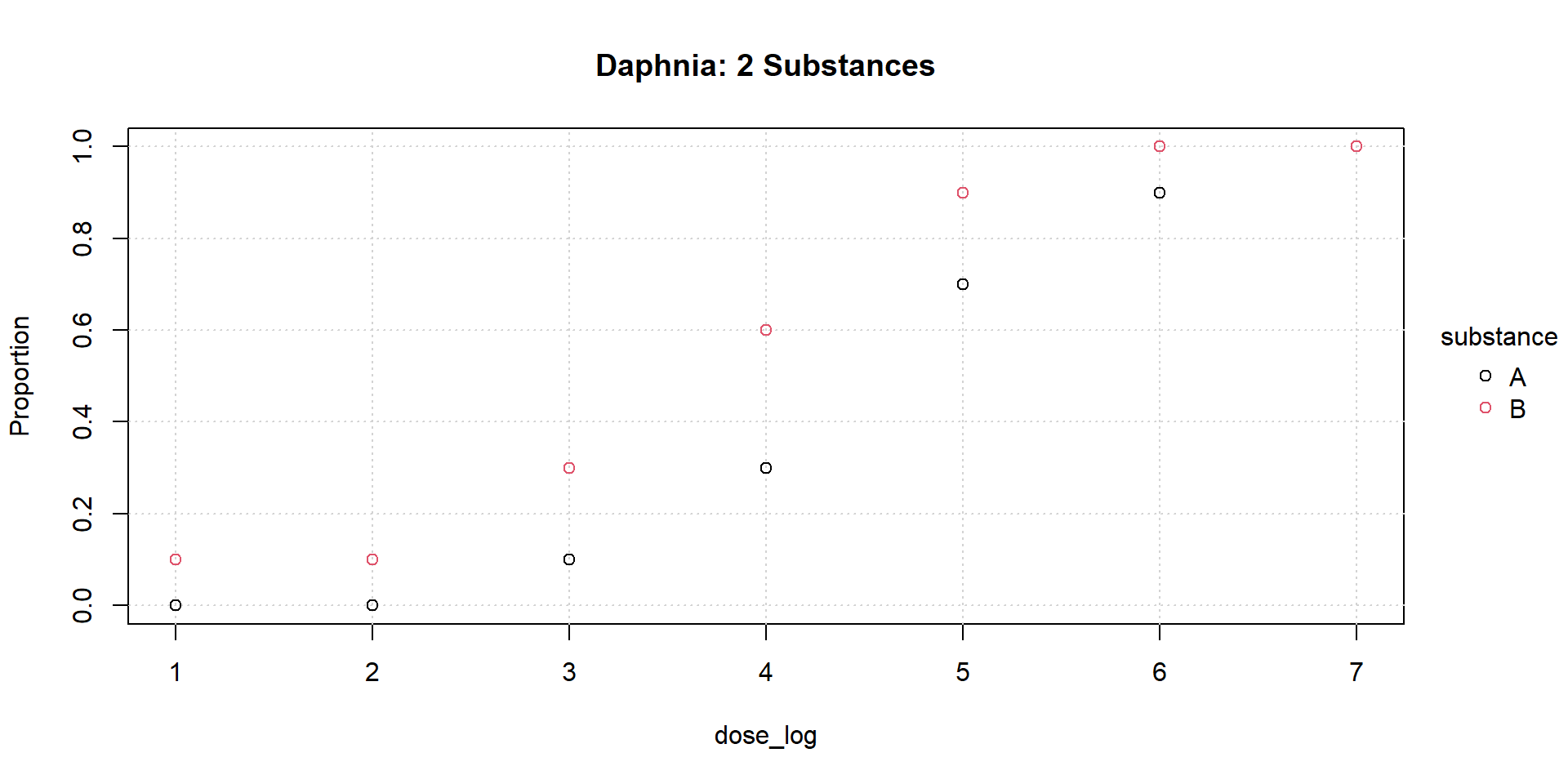
library("tinyplot")
plt(
I(dead / total) ~ dose_log | substance,
data = daphnia2,
type = "p",
main = "Daphnia: 2 Substances",
ylab = "Proportion",
grid = TRUE
)
Visualisierung
Code anzeigen
# Interaction was not significant --> use model without interaaction (+)
m_AB<- glm(
cbind(dead, total - dead) ~ dose_log + substance,
data = daphnia2,
family = binomial(link = "logit")
)
# create range of doses for a smooth plot
dose_range <- seq(1, 7, length.out = 100)
newdata <- expand.grid(dose_log = dose_range, substance = c("A", "B"))
# Predict probabilities using the model
newdata$prob <- predict(m_AB, newdata = newdata, type = "response")
# Plot the empirical proportions
plt(
I(dead / total) ~ dose_log | substance,
data = daphnia2,
type = "p",
main = "Daphnia: 2 Substances",
ylab = "Proportion",
grid = TRUE
)
# Overlay the GLM fit lines
plt(
prob ~ dose_log | substance,
data = newdata,
type = "l",
add = TRUE, # 'add = TRUE' acts like base R's lines()
lwd = 2
)
abline(h=0.5, col="grey")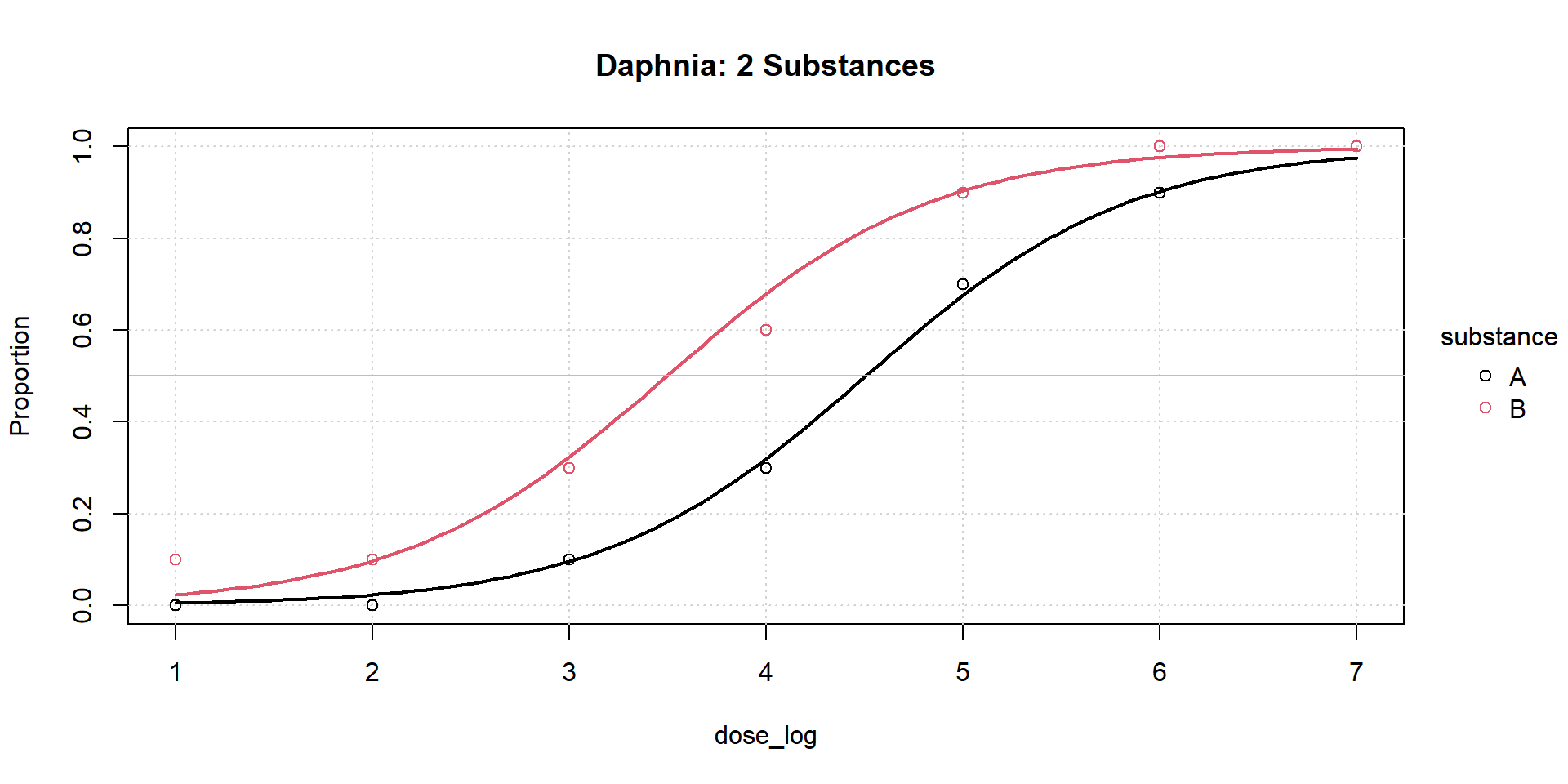
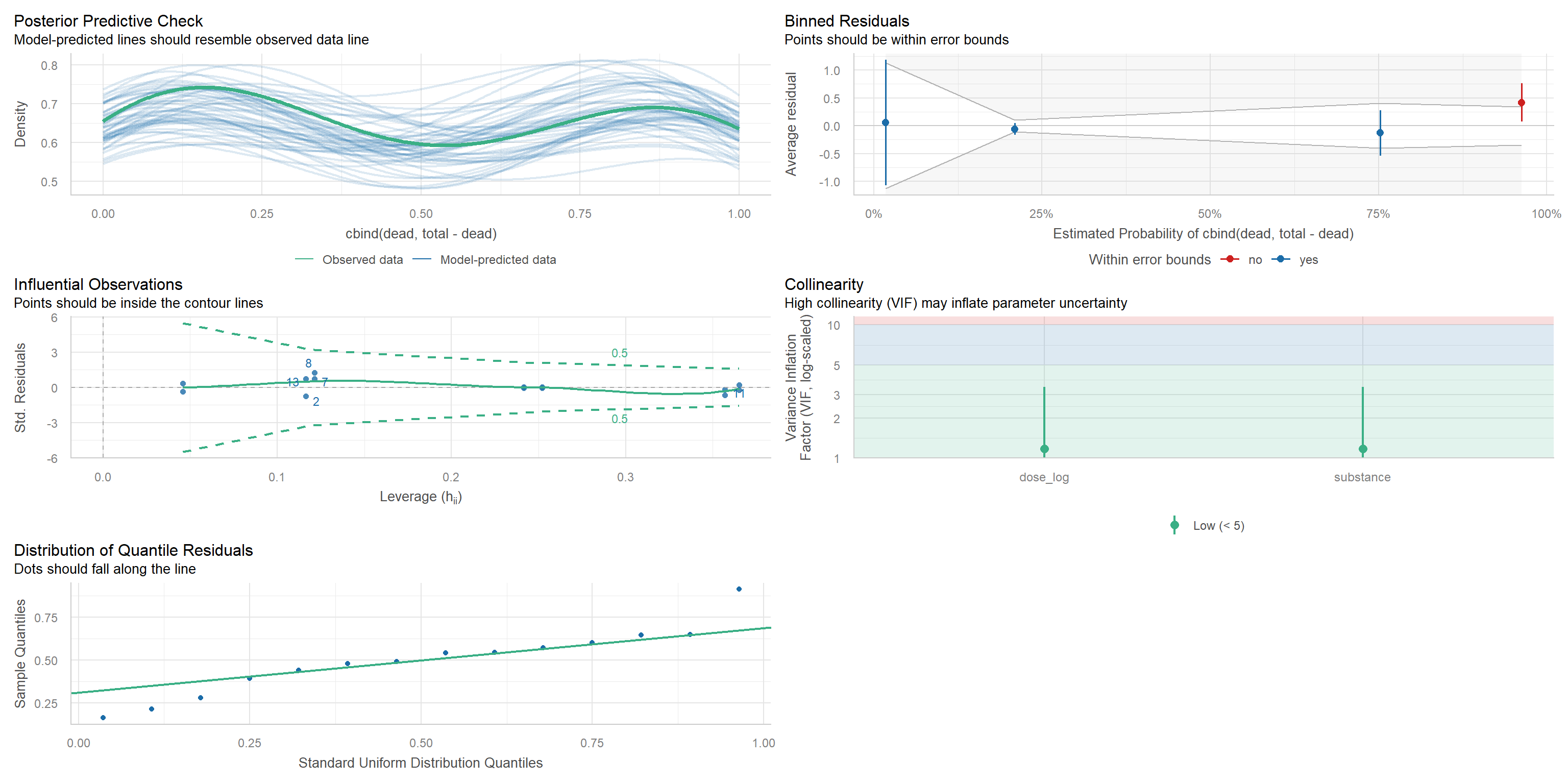
Diagnostik
library(performance)
library(see) # für bessere Plots
check_model(m_AB)