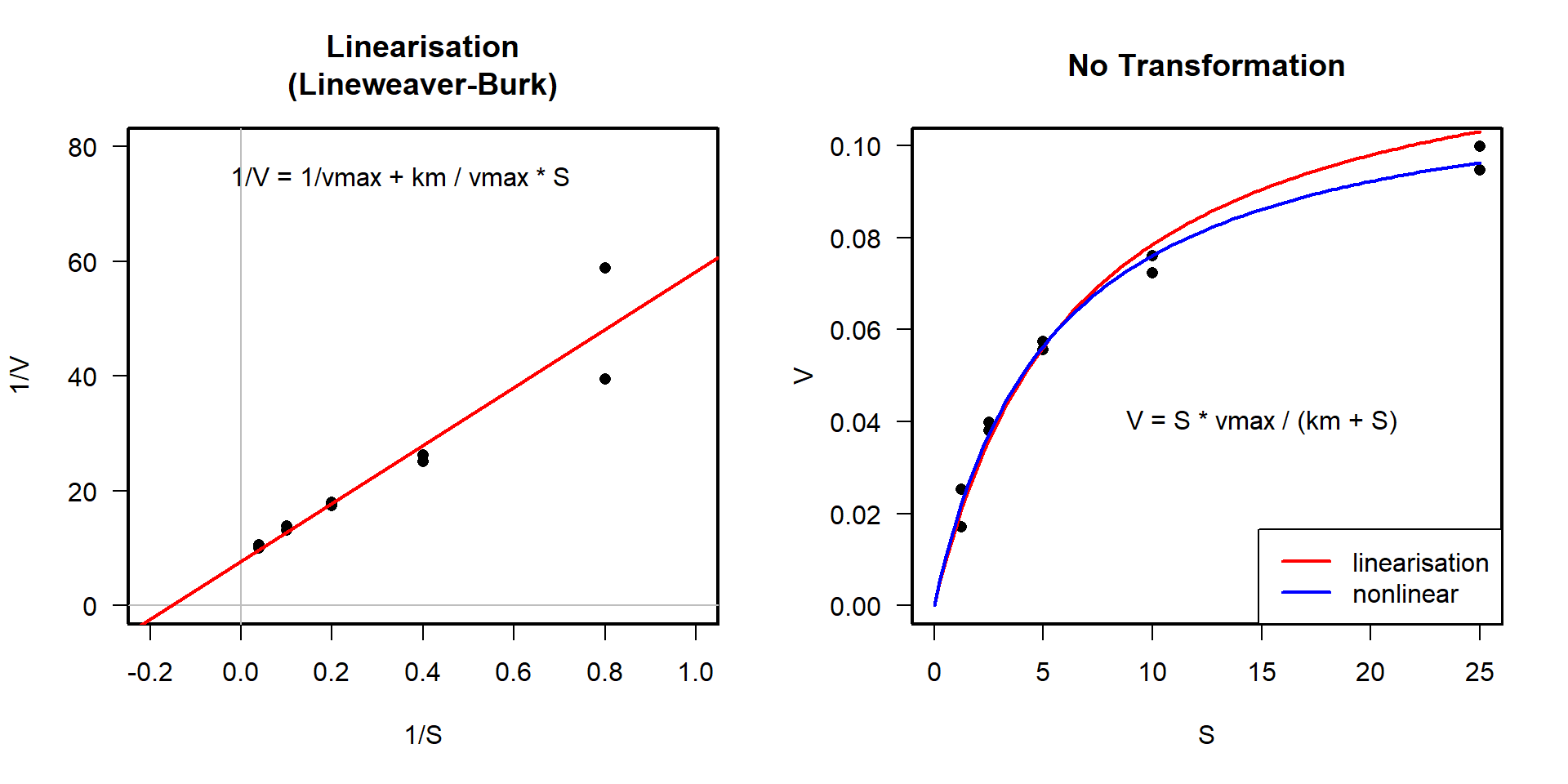
Linearisierung oder (echte) nichtlineare Regression?
Linearisierende Transformation
[>] Angemessen, wenn die Transformation die Homogenität der Varianzen verbessert. [+] Schnell, einfach und leicht zu implementieren. [+] Analytische Lösung liefert das globale Optimum. [-] Nur eine begrenzte Anzahl von Funktionen kann angepasst werden. [-] Kann zu einer falsch transformierten Fehlerstruktur und verzerrten Ergebnissen führen.
Nichtlineare Regression
[>] Geeignet, wenn die Fehlerstruktur homogen ist oder keine analytische Lösung existiert. [+] Ermöglicht Anpassung beliebiger Funktionen – sofern die Parameter identifizierbar sind. [-] Erfordert sorgfältige Auswahl von Startwerten. [-] Rechenintensiv – hoher Zeitaufwand. [-] Globales Optimum ist nicht garantiert – nur lokales Optimum möglich.
Empfehlung
Verwende nichtlineare Regression, wenn möglich – sie ist robuster und realistischer.
Nutze Linearisierung nur, wenn sie wirklich sinnvoll ist (z.B. Varianzstabilisierung).
Nichtlineare Regression in R: einfache exponentielle Regression
Modell anpassen
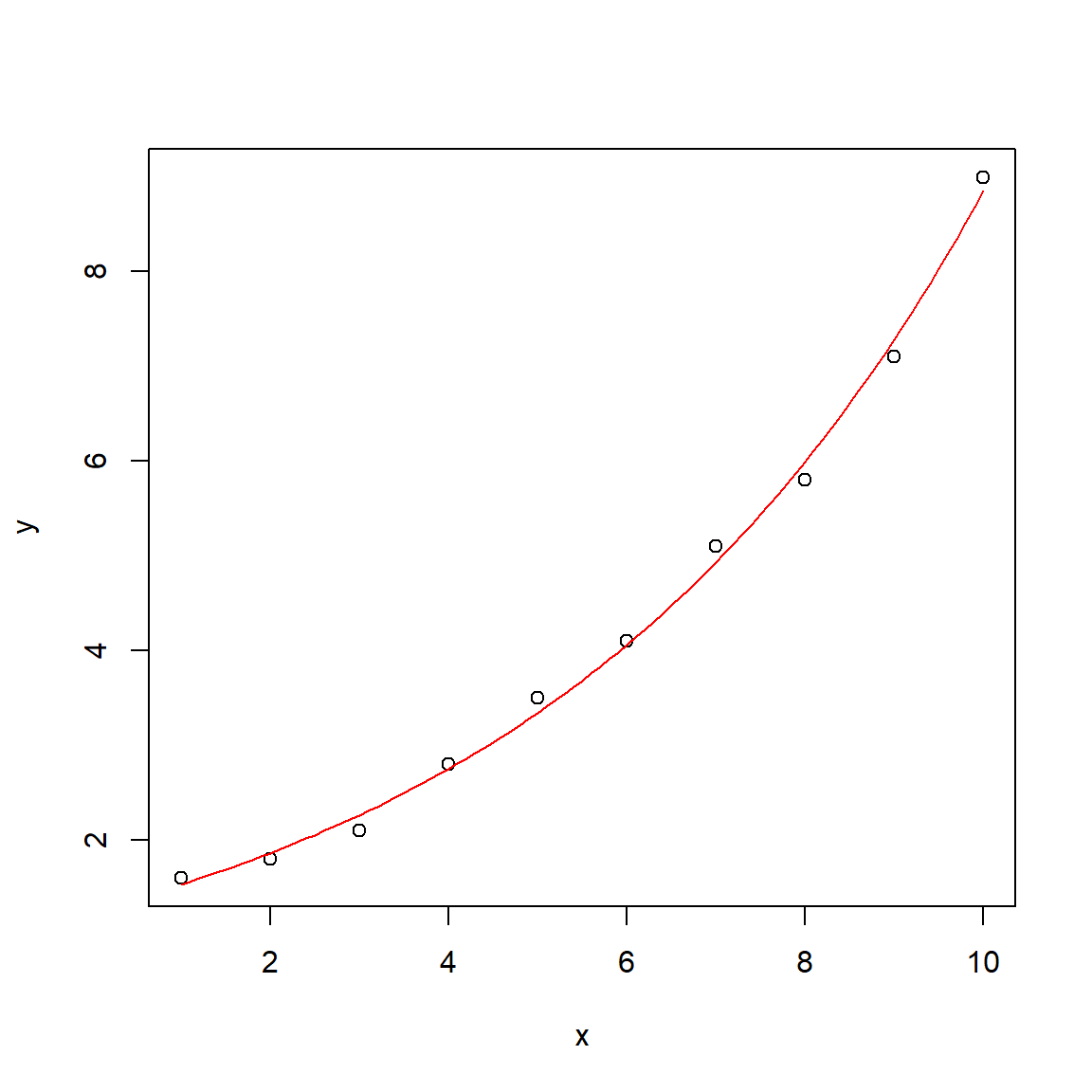
# Beispieldatenx <-1:10y <-c(1.6, 1.8, 2.1, 2.8, 3.5, 4.1, 5.1, 5.8, 7.1, 9.0)# Anfangsparameter für den Optimiererpstart <-c(a =1, b =1)# nichtlineare kleinste Quadratefit <-nls(y ~ a *exp(b * x), start = pstart)summary(fit)
Formula: y ~ a * exp(b * x)
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 1.263586 0.049902 25.32 6.34e-09 ***
b 0.194659 0.004716 41.27 1.31e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1525 on 8 degrees of freedom
Number of iterations to convergence: 13
Achieved convergence tolerance: 5.956e-08
Plotte Ergebnisse
# zusätzliche x-Werte, für eine geglättete Kurvex1 <-seq(1, 10, 0.1)y1 <-predict(fit, data.frame(x = x1))plot(x, y)lines(x1, y1, col ="red")
Angepasste Parameter
Formula: y ~ a * exp(b * x)
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 1.263586 0.049902 25.32 6.34e-09 ***
b 0.194659 0.004716 41.27 1.31e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1525 on 8 degrees of freedom
Number of iterations to convergence: 13
Achieved convergence tolerance: 5.956e-08
Estimate: die angepassten Parameter
Std. Error:\(s_{\bar{x}}\): zeigt die Zuverlässigkeit der Parameter
t- und p-Werte: Vorsicht bei der Interpretation!
In der nichtlinearen Regression sind p-Werte nicht verlässlich – sie basieren auf Approximationen.
Ein „nicht-signifikanter“ Parameter kann strukturrelevant sein.
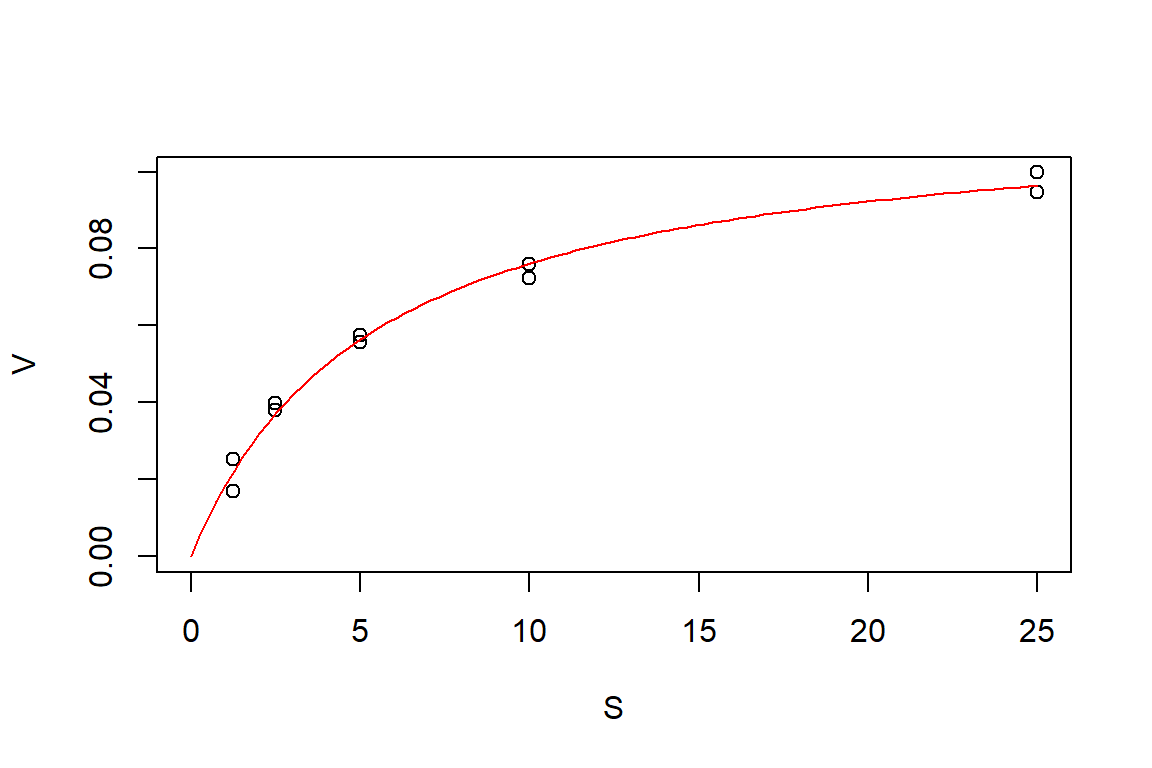
Formula: V ~ f(S, Vm, K)
Parameters:
Estimate Std. Error t value Pr(>|t|)
Vm 0.11713 0.00381 30.74 1.36e-09 ***
K 5.38277 0.46780 11.51 2.95e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.003053 on 8 degrees of freedom
Correlation of Parameter Estimates:
Vm
K 0.88
Number of iterations to convergence: 3
Achieved convergence tolerance: 6.678e-06
Plot
Anmerkung: Korrelation der Parameter
Hohe absolute Korrelationswerte deuten auf die Nichtidentifizierbarkeit von Parametern hin.
kritischer Wert hängt von den Daten ab
manchmal können bessere Startwerte oder ein anderer Optimierungsalgorithmus helfen
Praktische Hinweise
Daten immer plotten!
→ Visuelle Inspektion hilft, die Struktur zu erkennen und Startwerte zu finden.
Finde gute Ausgangswerte
→ Durch Nachdenken über die Biologie/Physik des Problems
→ Oder durch Probieren (z.B. mit plot(S, V) und schätzen der Kurve)
Vermeide extrem kleine oder große Zahlen
→ Reskaliere die Variablen auf Werte zwischen etwa 0.001 und 1000
→ Verbessert Stabilität und Konvergenz der Optimierung
Beginne einfach
→ Starte mit einer einfachen Funktion
→ Füge nach und nach Terme und Parameter hinzu – Schritt für Schritt
Interpretiere Signifikanz vorsichtig
→ p-Werte in nichtlinearen Modellen sind nicht verlässlich
→ Ein „nicht signifikanter“ Parameter kann strukturrelevant sein
→ Sein Wegfall macht das Modell ungültig – nicht ausschließen!
Wichtig:
Die Qualität eines Modells hängt nicht von p-Werten ab – sondern von Plausibilität, Anpassungsgüte und Vorhersagekraft.
Weiterführende Literatur
Paket growthrates für Wachstumskurven: https://cran.r-project.org/package=growthrates
Paket FME für komplexere Modellanpassungsaufgaben (Identifizierbarkeitsanalyse, eingeschränkte Optimierung, mehrere abhängige Variablen und MCMC): (Soetaert & Petzoldt, 2010), https://cran.r-project.org/package=FME
Mehr über Optimierung in R: https://cran.r-project.org/web/views/Optimization.html
Anhang
Lineweaver-Burk-Transformation vs. nichtlineare Anpassung
Price, W. L. (1977). A controlled random search procedure for global optimization. The Computer Journal, 20(4), 367–370.
Price, W. L. (1983). Global optimization by controlled random search. Journal of Optimization Theory and Applications, 40(3), 333–348.
Soetaert, K., & Petzoldt, T. (2010). Inverse modelling, sensitivity and monte carlo analysis in R using package FME. Journal of Statistical Software, 33(3), 1–28. https://doi.org/10.18637/jss.v033.i03
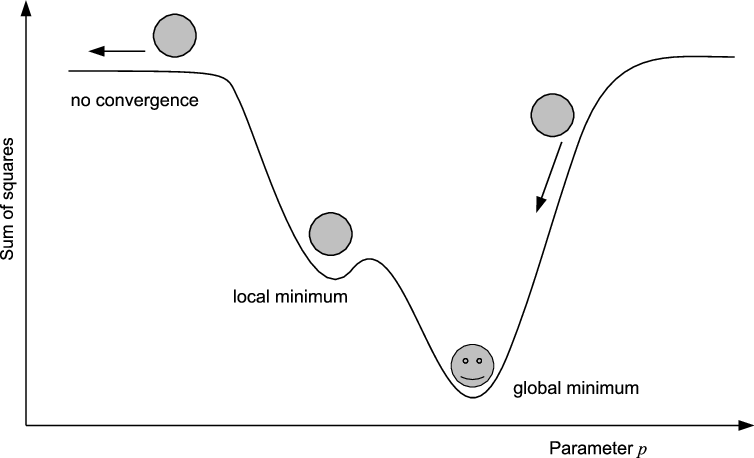
 Die Newton-Methode (
Die Newton-Methode (