| treat | replicate 1 | replicate 2 | replicate 3 |
|---|---|---|---|
| Fertilizer | 0.020 | -0.217 | -0.273 |
| F. open | 0.940 | 0.780 | 0.555 |
| F.+sugar | 0.188 | -0.100 | 0.020 |
| F.+CaCO3 | 0.245 | 0.236 | 0.456 |
| Bas.med. | 0.699 | 0.727 | 0.656 |
| A.dest | -0.010 | 0.000 | -0.010 |
| Tap water | 0.030 | -0.070 | NA |
07-ANOVA und ANCOVA
Angewandte Statistik – Ein Praxiskurs
2025-12-13
Ein Praxisbeispiel
Suche nach einem geeigneten Medium für Wachstumsexperimente mit Grünalgen
- Schulprojekt aus “Jugend Forscht”
- geeignet für Kurse in Schule und Studium
- preisgünstig, einfach zu handhaben

Idee
- Verwendung eines kommerziellen Düngers mit den Hauptnährstoffen N und P
- Mineralwasser mit Spurenelementen
- Enthält stilles Mineralwasser genügend \(\mathrm{CO_2}\)?
- testen, wie man die Verfügbarkeit von \(\mathrm{CO_2}\) für die Photosynthese verbessern kann
Versuchsaufbau

- jede Behandlung mit 3 Wiederholungen
- randomisierte Platzierung auf dem Schüttler
- 16:8 Licht:Dunkel-Zyklus
- Transmissionsmessung direkt in den Flaschen mit einem selbstgebauten Messgerät
Ergebnisse
 Dünger – offene Flasche – + Zucker – + CaCO3 – Basalmedium – A. dest – Leitungswasser
Dünger – offene Flasche – + Zucker – + CaCO3 – Basalmedium – A. dest – Leitungswasser
Boxplot
boxplot(growth ~ treat, data = algae)
abline(h = 0, lty = "dashed", col = "grey")
Streifendiagramm
stripchart(growth ~ treat, data = algae, vertical = TRUE)
Besser als Boxplot, denn wir haben nur 2-3 Wiederholungen. Boxplot braucht mehr.
Dann wird eine lineare Regression angewandt
plot(weight ~ code, data = clem, axes = FALSE)
m <- lm(weight ~ code, data = clem)
axis(1, at = c(1,2), labels = c("EB", "EP")); axis(2); box()
abline(m, col = "blue")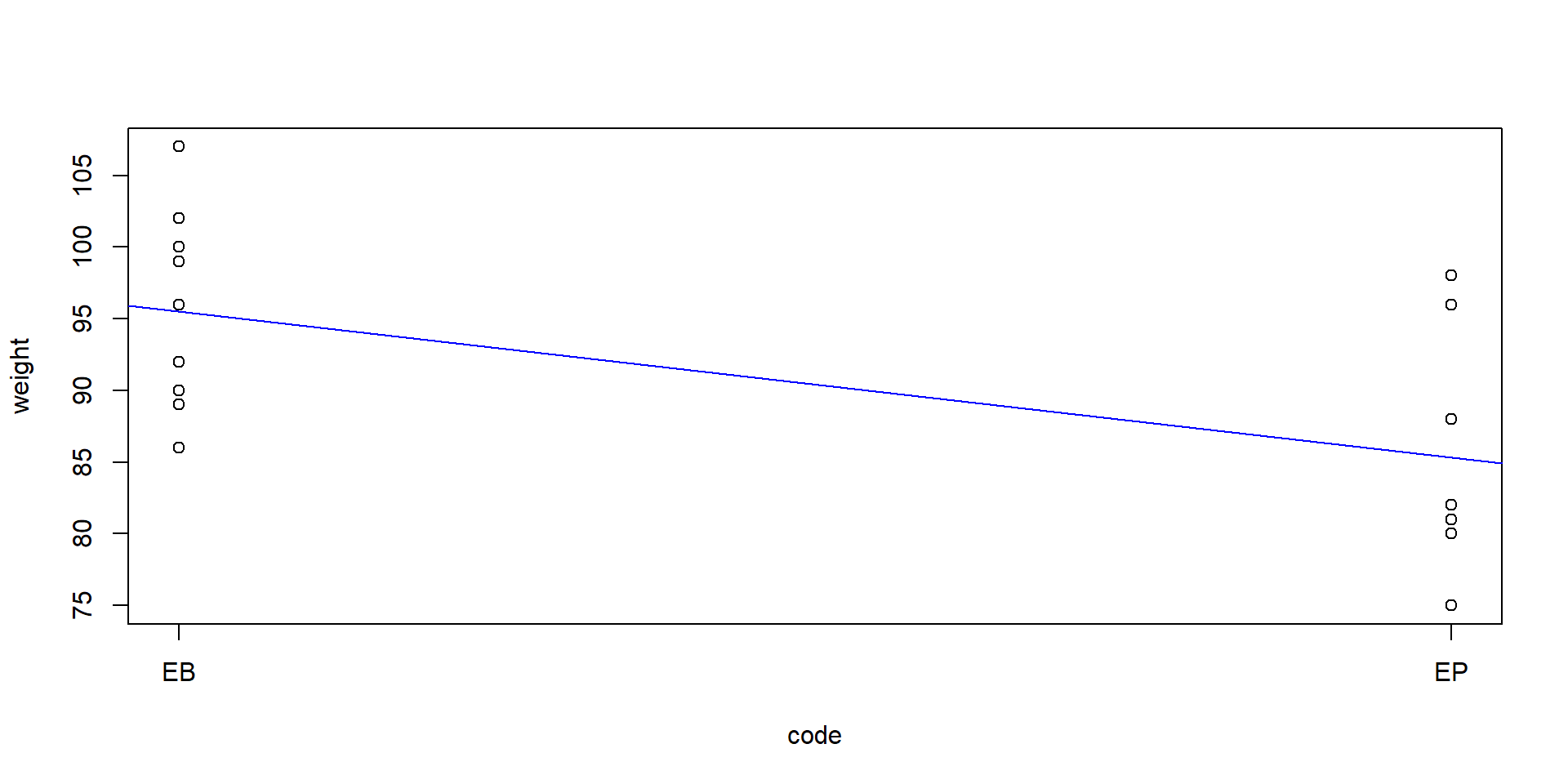
Grafische Darstellung
par(las = 1) # Achsenbeschriftungen horizontal
par(mar = c(4, 10, 3, 1)) # mehr Platz für lange Gruppenbezeichnungen
plot(tk)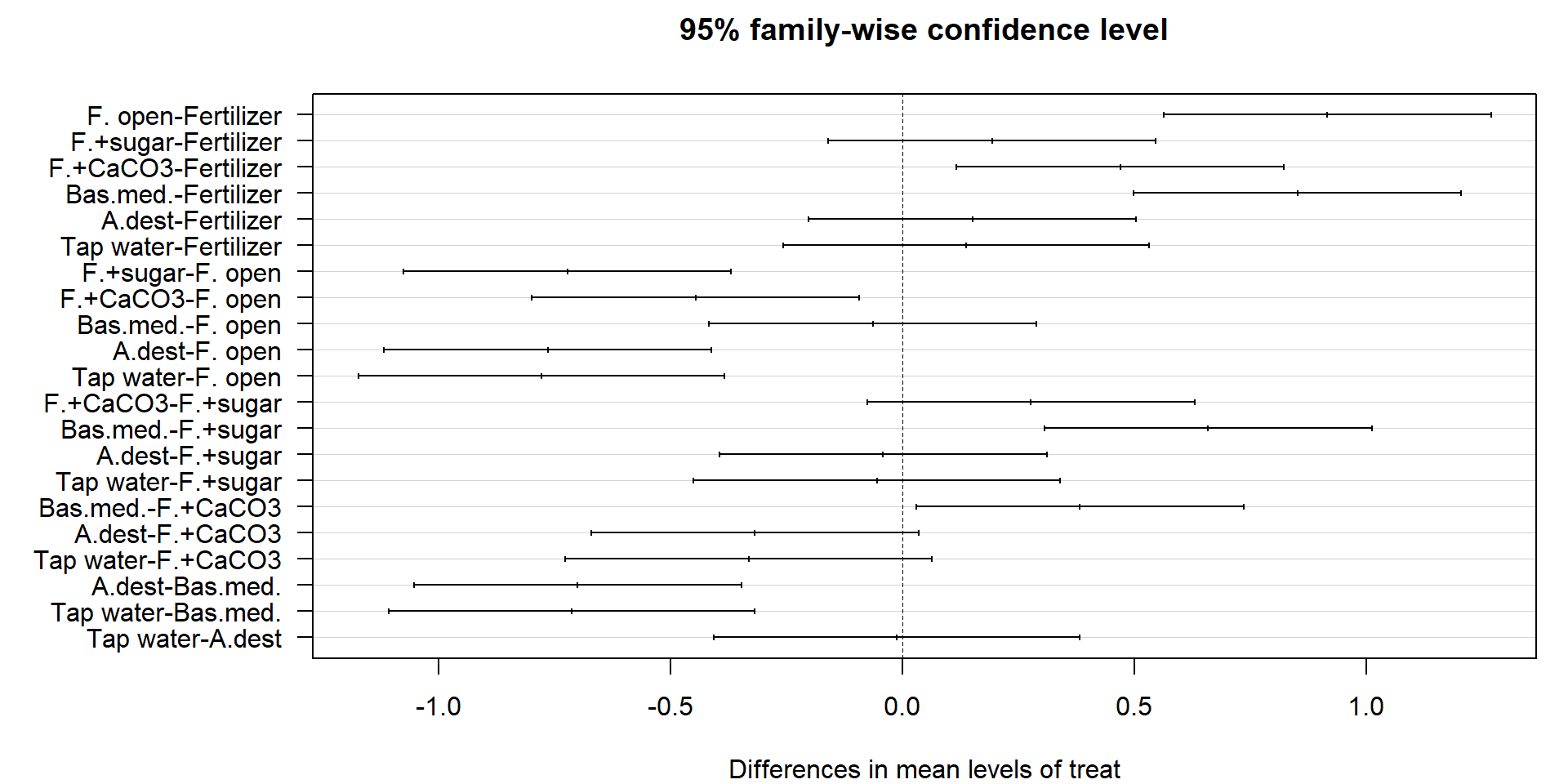
ANOVA Annahmen und Diagnostik
Für die ANOVA gelten dieselben Annahmen wie für das lineare Modell.
- Unabhängigkeit der Fehler
- Homogenität der Varianzen (Homoskedastizität)
- Annähernde Normalverteilung der Fehler
Grafische Diagnostik wird bevorzugt – sie ist robuster als numerische Tests.
par(mfrow=c(2, 2))
plot(m)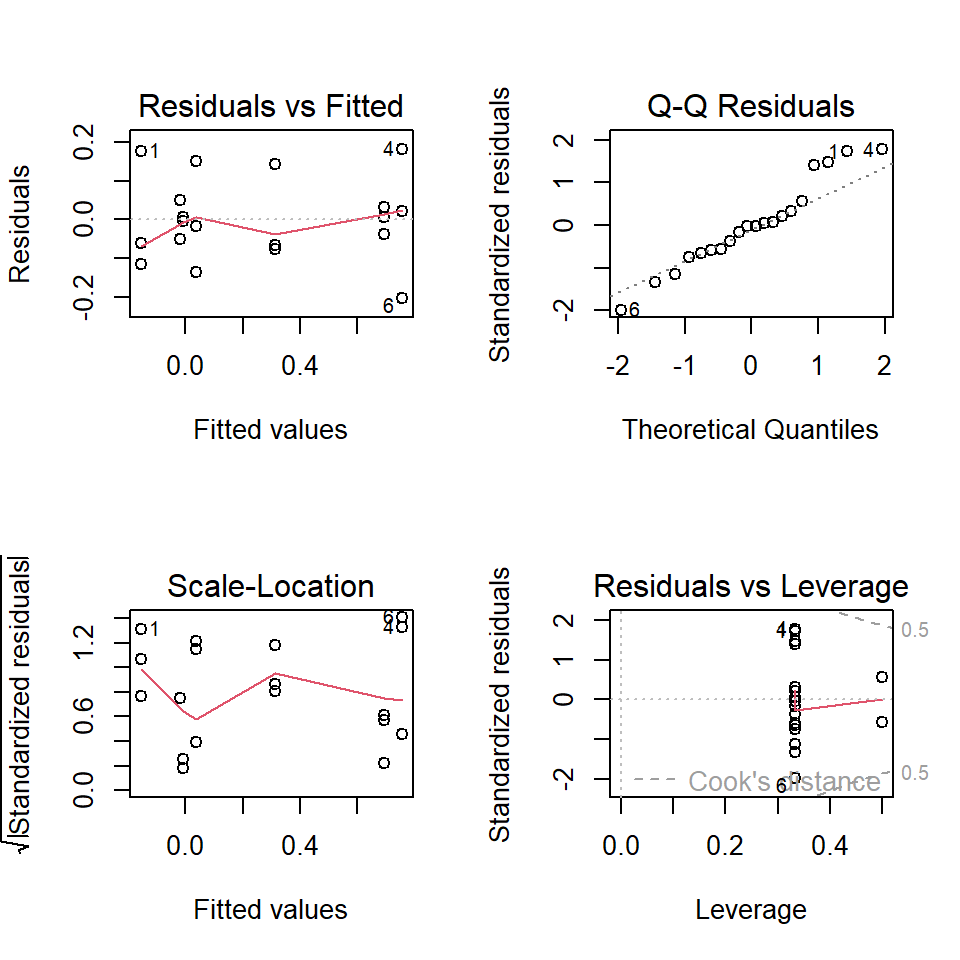
Test auf Normalverteilung
- Teste die Residuen, nicht die Rohdaten!
- Der Shapiro-Wilk-Test wird nicht mehr empfohlen:
- Bei kleinen Stichproben: hohe Wahrscheinlichkeit für Fehlertyp II
(keine Ablehnung, obwohl Unterschiede existieren). - Bei großen Stichproben: hohe Wahrscheinlichkeit für Fehlertyp I
(Ablehnung, obwohl Unterschiede vernachlässigbar sind.)
- Bei kleinen Stichproben: hohe Wahrscheinlichkeit für Fehlertyp II
- Empfohlen: Grafische Methoden – insbesondere der QQ-Plot.
qqnorm(residuals(m))
qqline(residuals(m))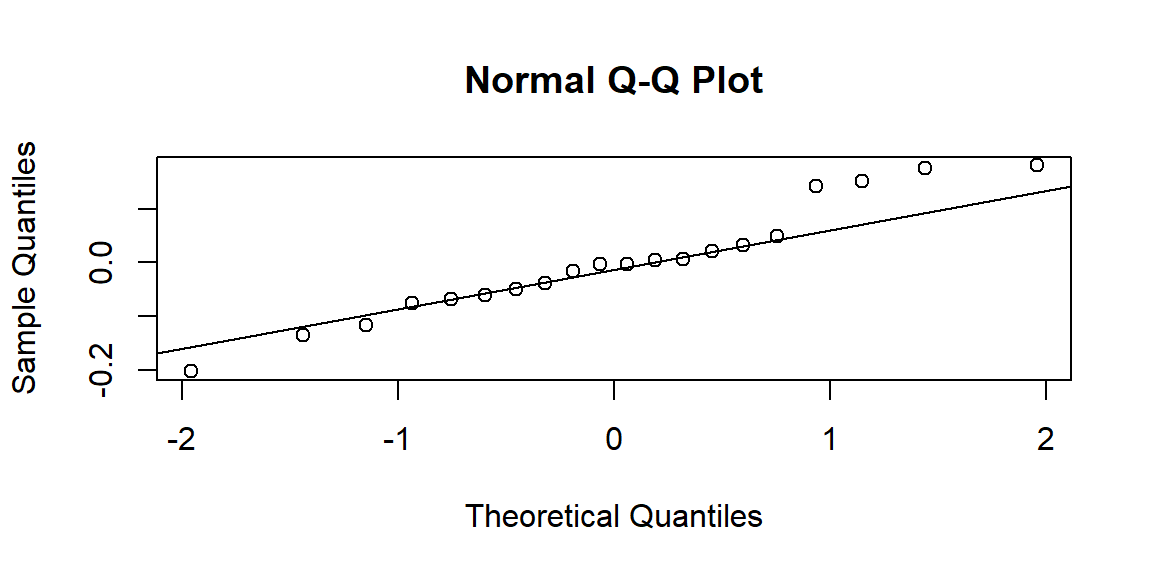
Lineares Modell und ANOVA
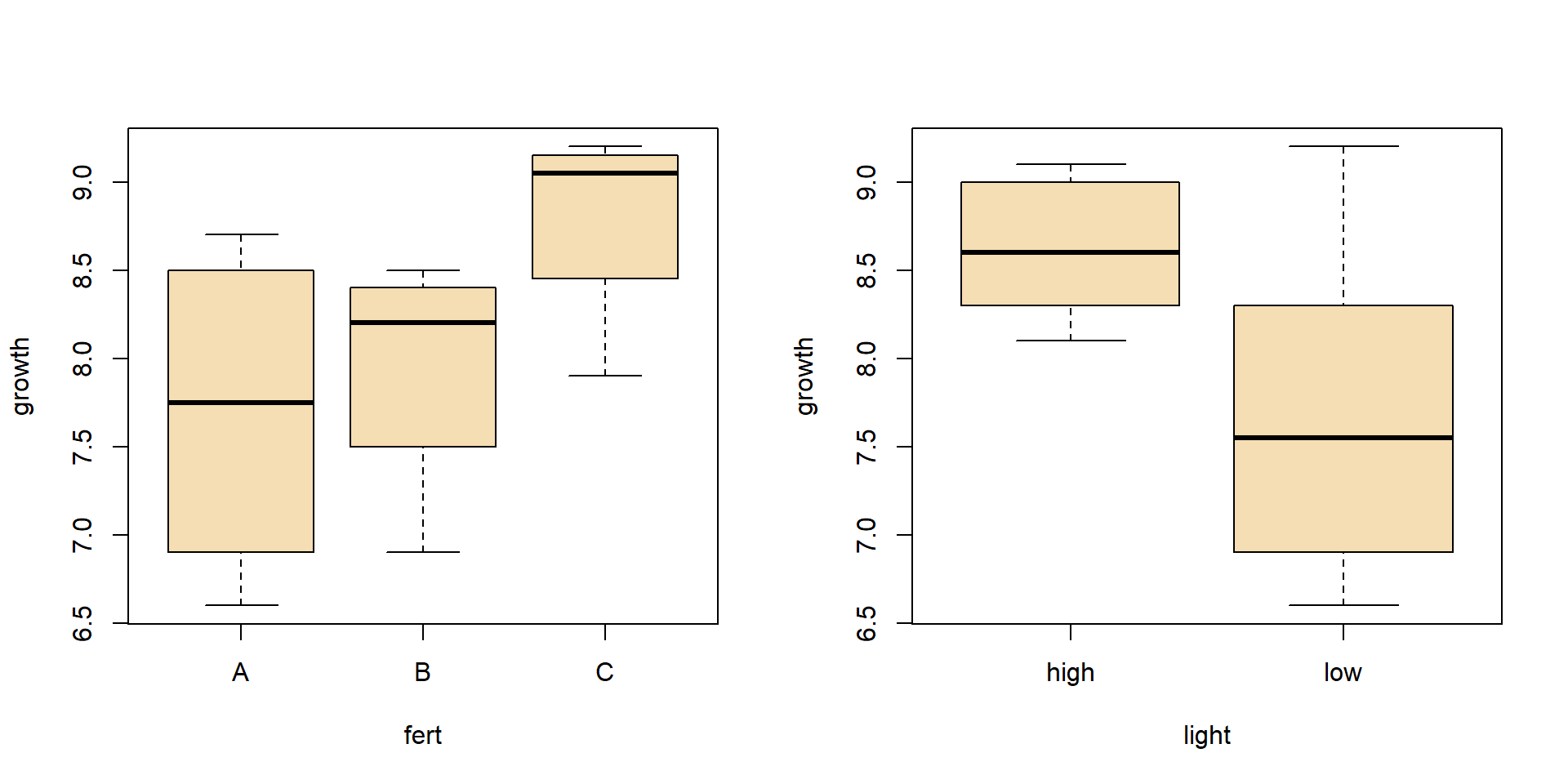
ANOVA
m <- lm(growth ~ light * fert, data = plants)
anova(m)Analysis of Variance Table
Response: growth
Df Sum Sq Mean Sq F value Pr(>F)
light 1 2.61333 2.61333 7.2258 0.03614 *
fert 2 2.66000 1.33000 3.6774 0.09069 .
light:fert 2 0.68667 0.34333 0.9493 0.43833
Residuals 6 2.17000 0.36167
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interaktionsplot
with(plants, interaction.plot(fert, light, growth,
col = c("orange", "brown"), lty = 1, lwd = 2))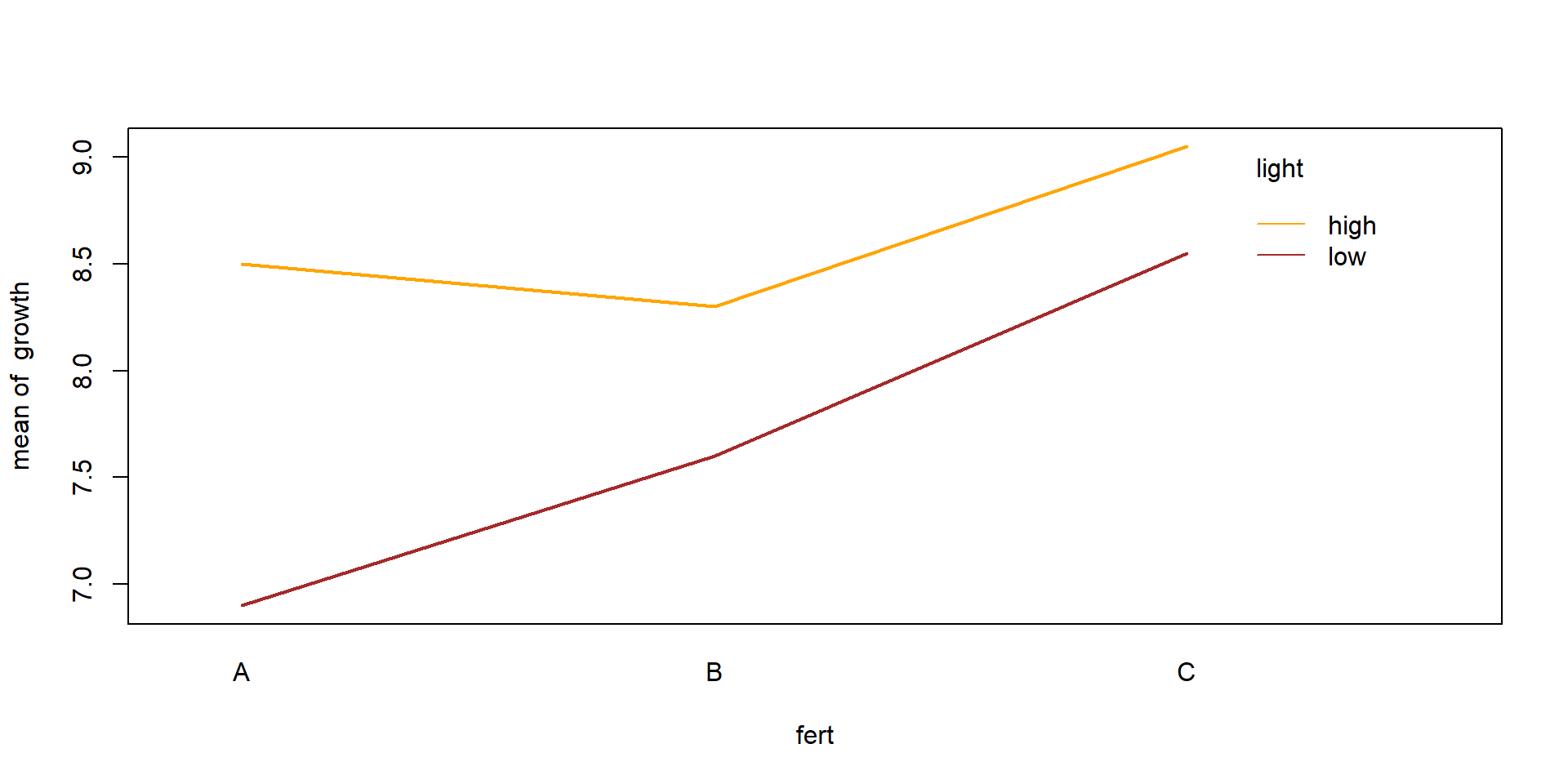
- Wenn die Linien nicht parallel sind, deutet es auf eine Wechselwirkung hin.
Diagnostik II
par(mfrow=c(1, 2))
par(cex=1.2, las=1)
qqnorm(residuals(m))
qqline(residuals(m))
plot(residuals(m)~fitted(m))
abline(h=0)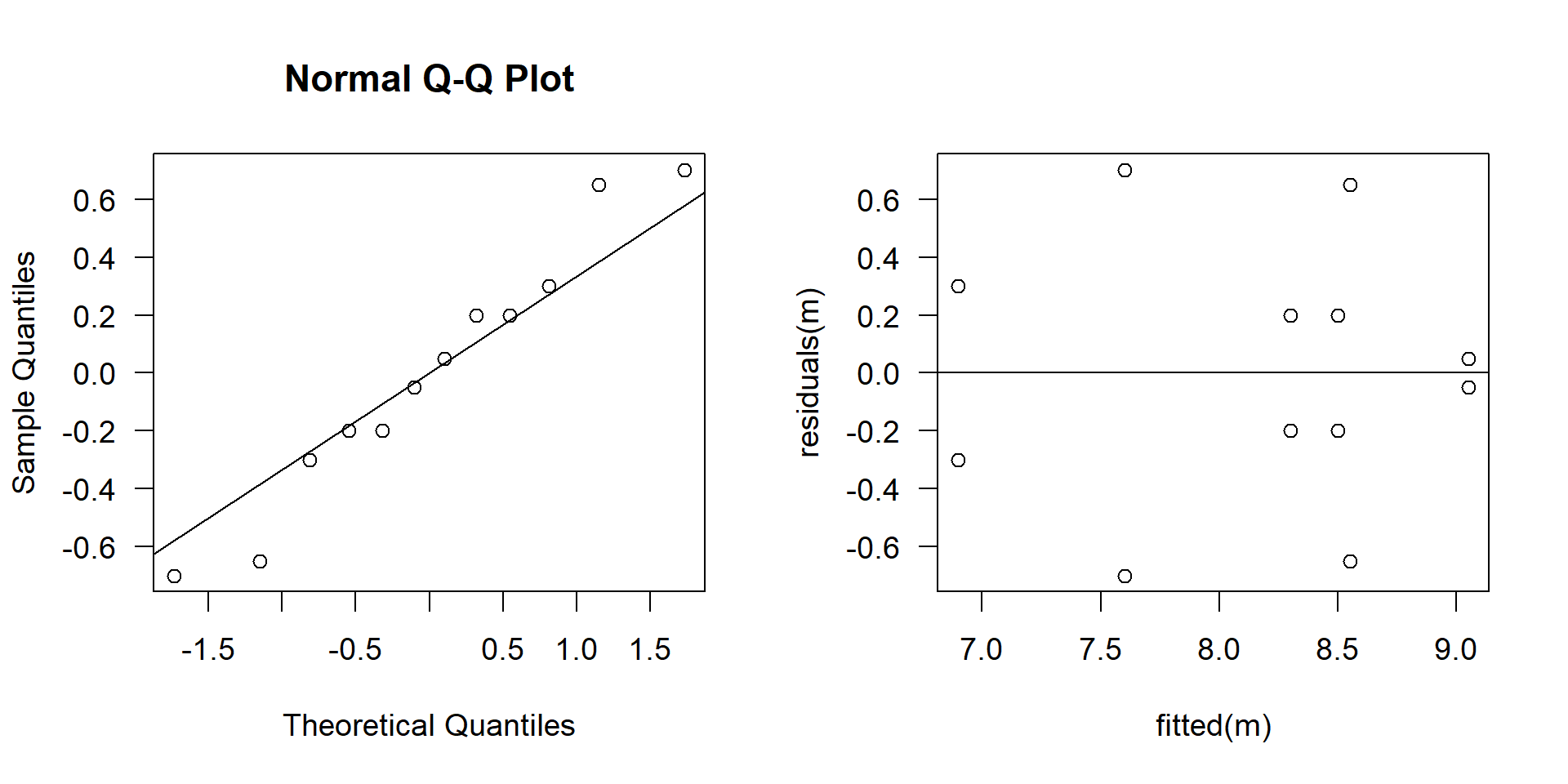
fligner.test(growth ~ interaction(light, fert), data=plants)
Fligner-Killeen test of homogeneity of variances
data: growth by interaction(light, fert)
Fligner-Killeen:med chi-squared = 10.788, df = 5, p-value = 0.05575Residuen: sehen in Ordnung aus und der p-Wert des Fligner-Tests ist noch ok.
Ansatz 1: einfache ANOVA
par(mar=c(4, 8, 2, 1), las=1)
m <- lm(mu ~ treat, data=mcyst)
anova(m)Analysis of Variance Table
Response: mu
Df Sum Sq Mean Sq F value Pr(>F)
treat 2 0.00053293 2.6647e-04 8.775 0.004485 **
Residuals 12 0.00036440 3.0367e-05
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1plot(TukeyHSD(aov(m)))
ANCOVA
Statistische Frage
- Vergleich von Regressionslinien zwischen Gruppen
- Ähnlich wie bei der ANOVA, enthält aber auch metrische Variablen (Kovariaten)
- Haben Gruppen unterschiedliche Anfangswerte (Intercept) und/oder unterschiedliche Steigungen (Slope)?
Beispiel
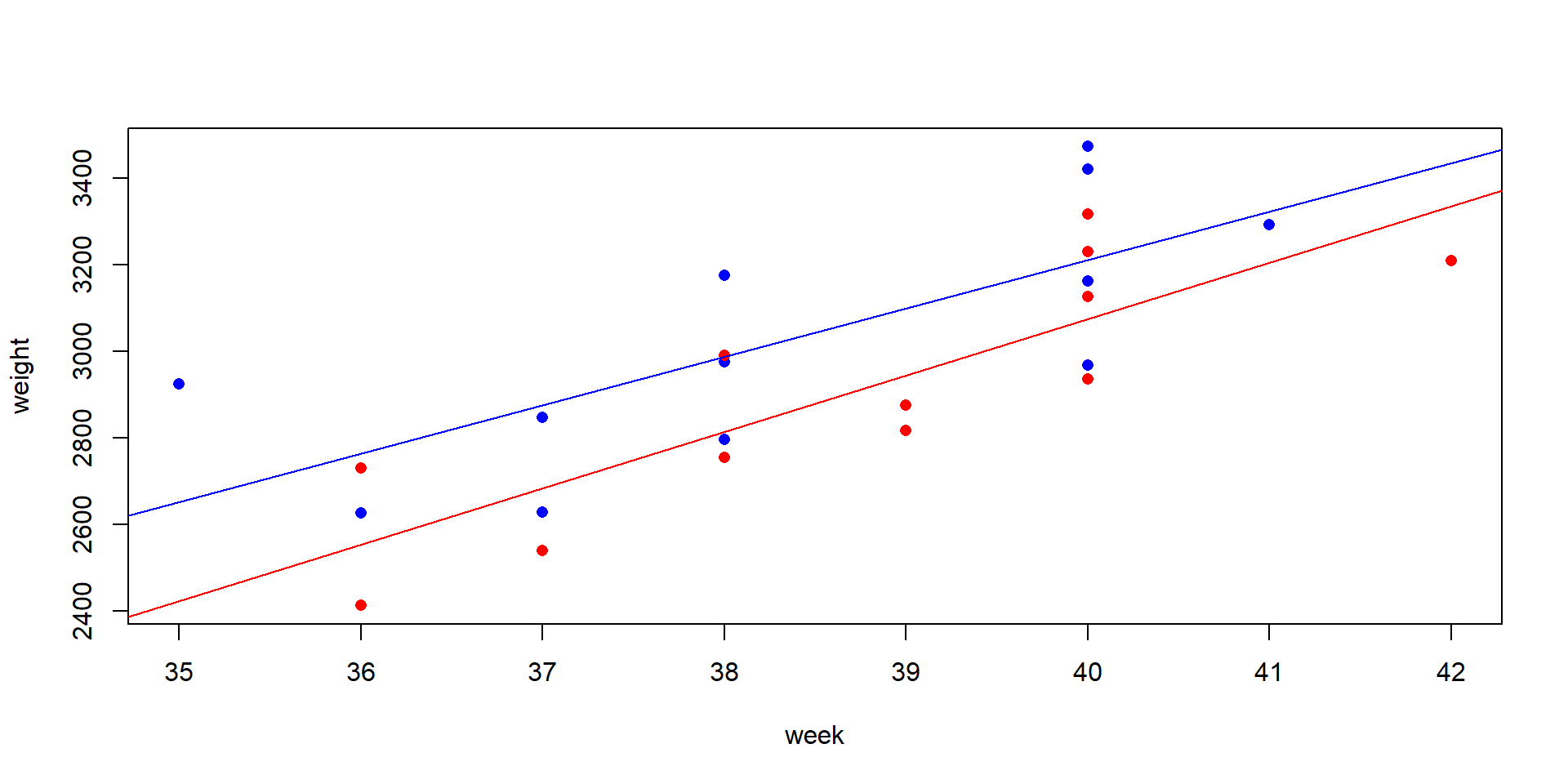
Annette Dobsons Geburtsgewichts-Daten – aus einem Statistik-Lehrbuch (Dobson, 2013): Geburtsgewicht von Jungen und Mädchen in Abhängigkeit von der Schwangerschaftswoche.
Warum nicht einfach einen t-Test durchführen?
boxplot(weight ~ gender,data = dobson, ylab = "weight")t.test(weight ~ gender, data = dobson, var.equal = TRUE)
Two Sample t-test
data: weight by gender
t = 0.97747, df = 22, p-value = 0.339
alternative hypothesis: true difference in means between group M and group F is not equal to 0
95 percent confidence interval:
-126.3753 351.7086
sample estimates:
mean in group M mean in group F
3024.000 2911.333 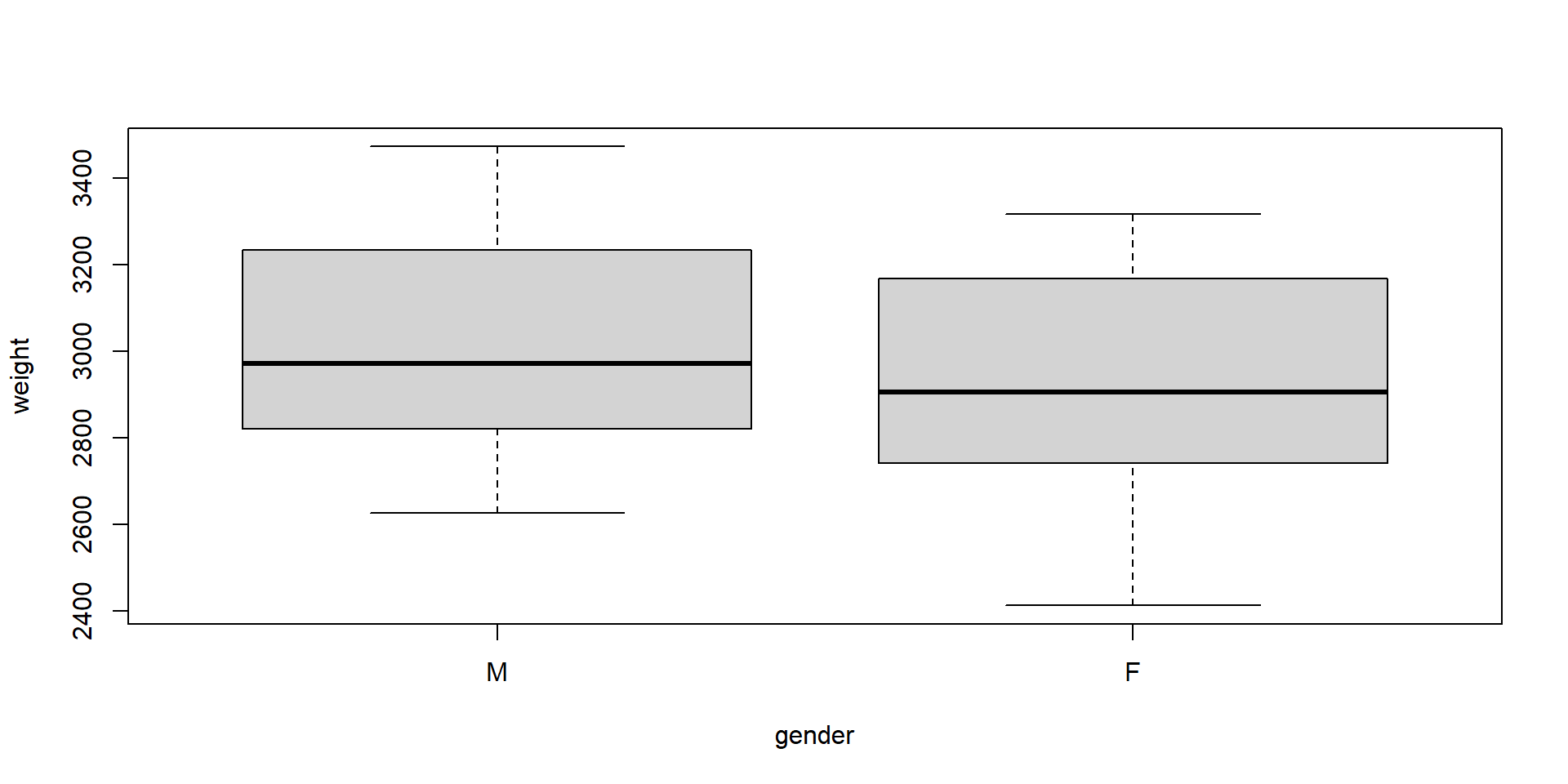
- Der t-Test zeigt keine signifikante Differenz und der Boxplot zeigt starke Überlappung.
- Aber: Der t-Test ignoriert die Schwangerschaftswoche, eine wichtige Kovariate.
ANCOVA: Berücksichtigung der Kovariate
m <- lm(weight ~ week * gender, data = dobson)
anova(m)Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
week 1 1013799 1013799 31.0779 1.862e-05 ***
gender 1 157304 157304 4.8221 0.04006 *
week:gender 1 6346 6346 0.1945 0.66389
Residuals 20 652425 32621
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1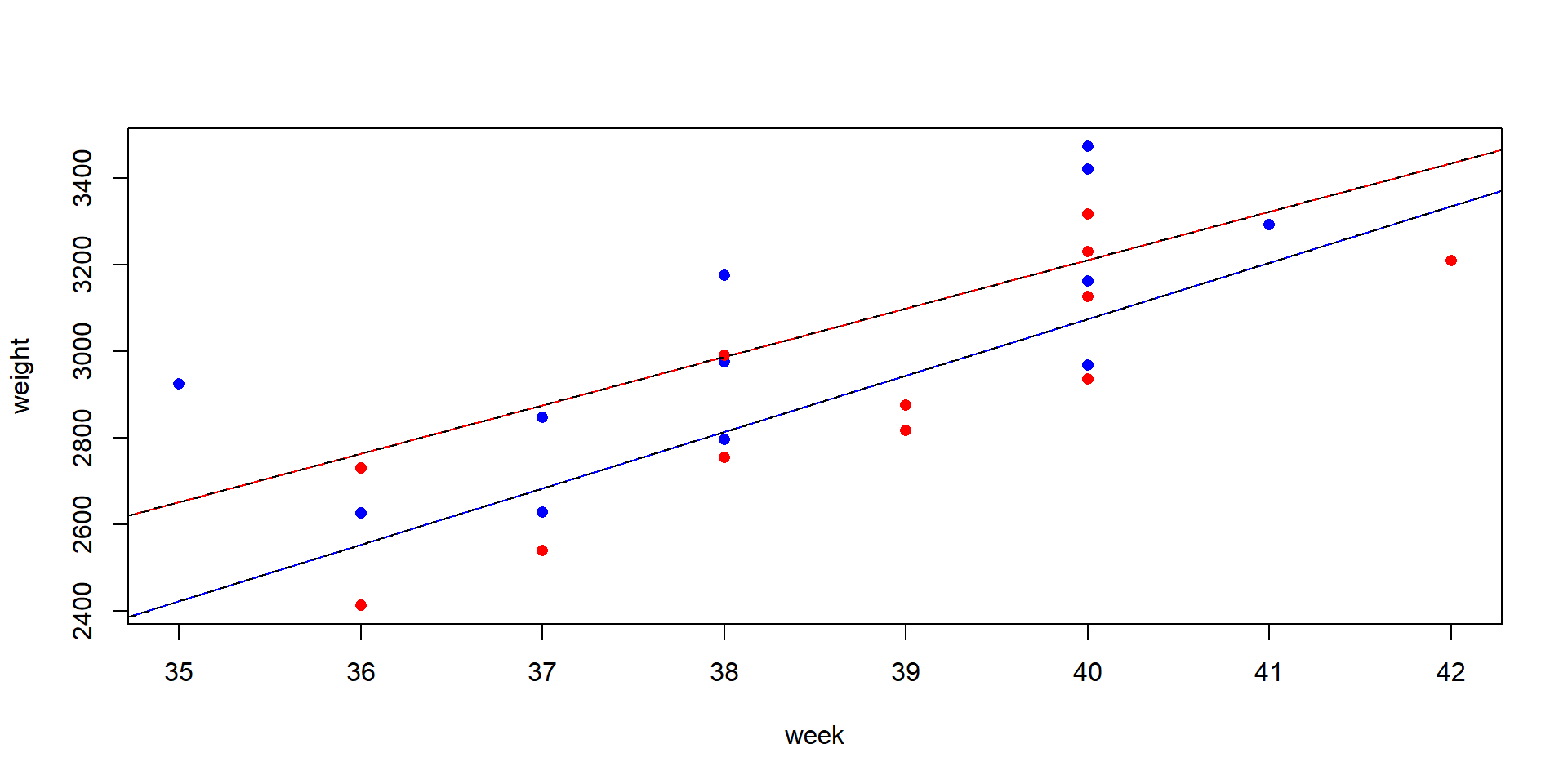
Beispiel: Aus Gründen, die wir später besprechen, muss die Kovariate week als erstes in der Modellformel stehen.
Typ II ANOVA: Beispiel
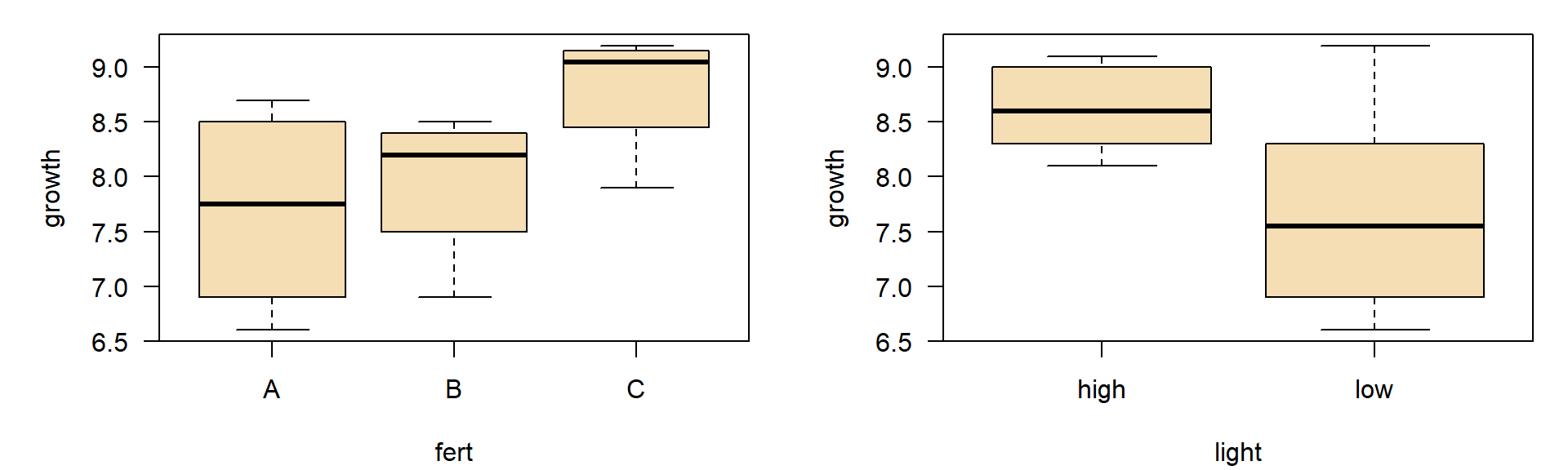
library("car")
m <- lm(growth ~ light * fert, data = plants)
Anova(m, type="II")Anova Table (Type II tests)
Response: growth
Sum Sq Df F value Pr(>F)
light 2.61333 1 7.2258 0.03614 *
fert 2.66000 2 3.6774 0.09069 .
light:fert 0.68667 2 0.9493 0.43833
Residuals 2.17000 6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1