06-Lineare Regression
Angewandte Statistik – Ein Praxiskurs
2025-12-13
Das lineare Modell
\[ y_i = \alpha + \beta_1 x_{i,1} + \beta_2 x_{i,2} + \cdots + \beta_p x_{i,p} + \varepsilon_i \]
Grundlage vieler statistischer Verfahren
- Lineare Regression einschließlich einiger (auf den ersten Blick) „nichtlinearer“ Funktionen
- Tests für zwei oder mehr Stichproben oder Faktoren: ANOVA, ANCOVA, GLM…
- Multivariate Statistik (z. B. PCA)
- Zeitreihenanalyse (z. B. ARIMA)
- Imputation (Schätzung von fehlenden Werten)
Methode der kleinsten Quadrate
\[ RSS = \sum_{i=1}^n (y_i - \hat{y}_i)^2 = \sum_{i=1}^n \varepsilon^2 \qquad \text{(residual sum of squares)} \]
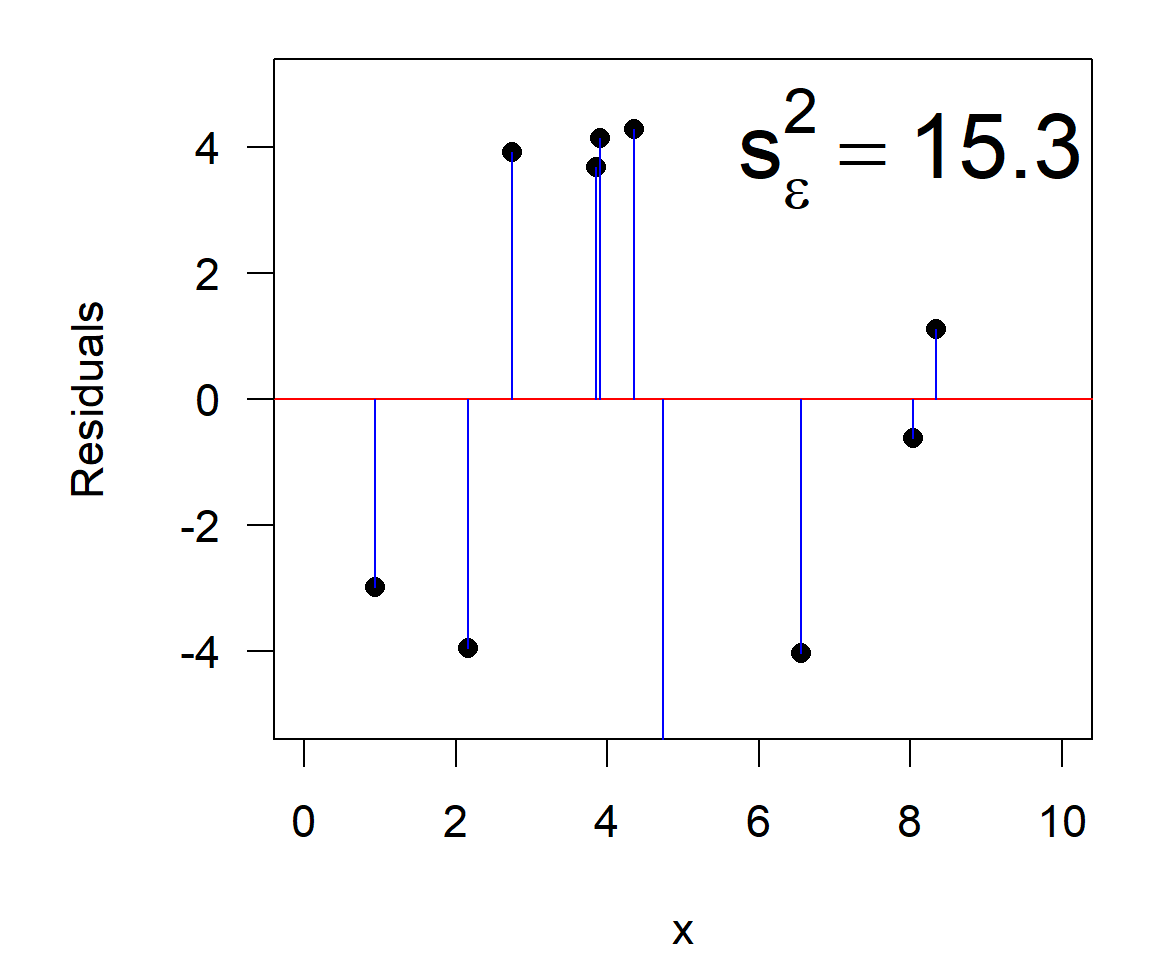
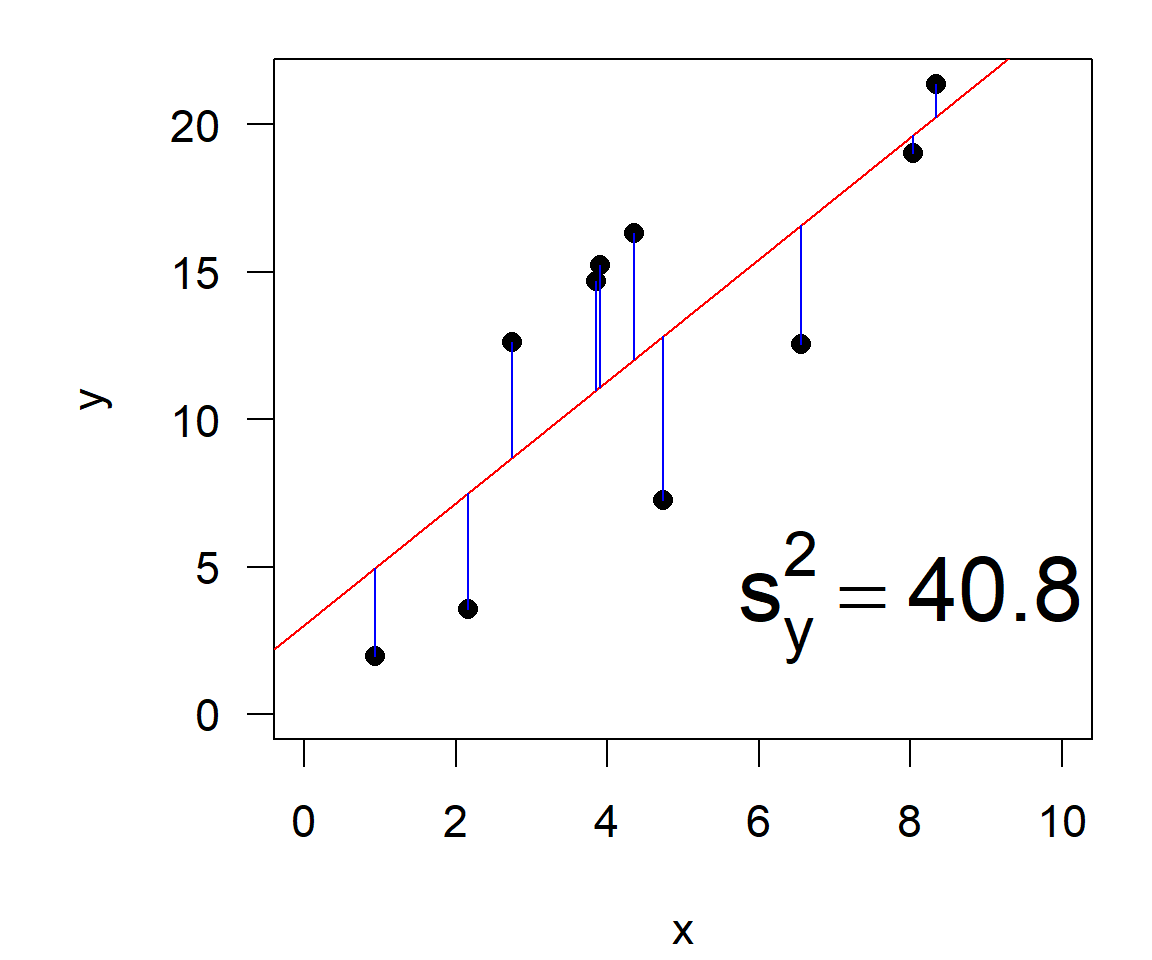
\[\begin{align} \text{Gesamtvarianz} &= \text{erklärte Varianz} & + & \text{Restvarianz}\\ ^2_y &= s^2_{y|x} & + & s^2_{\varepsilon} \end{align}\]
Diagnostik
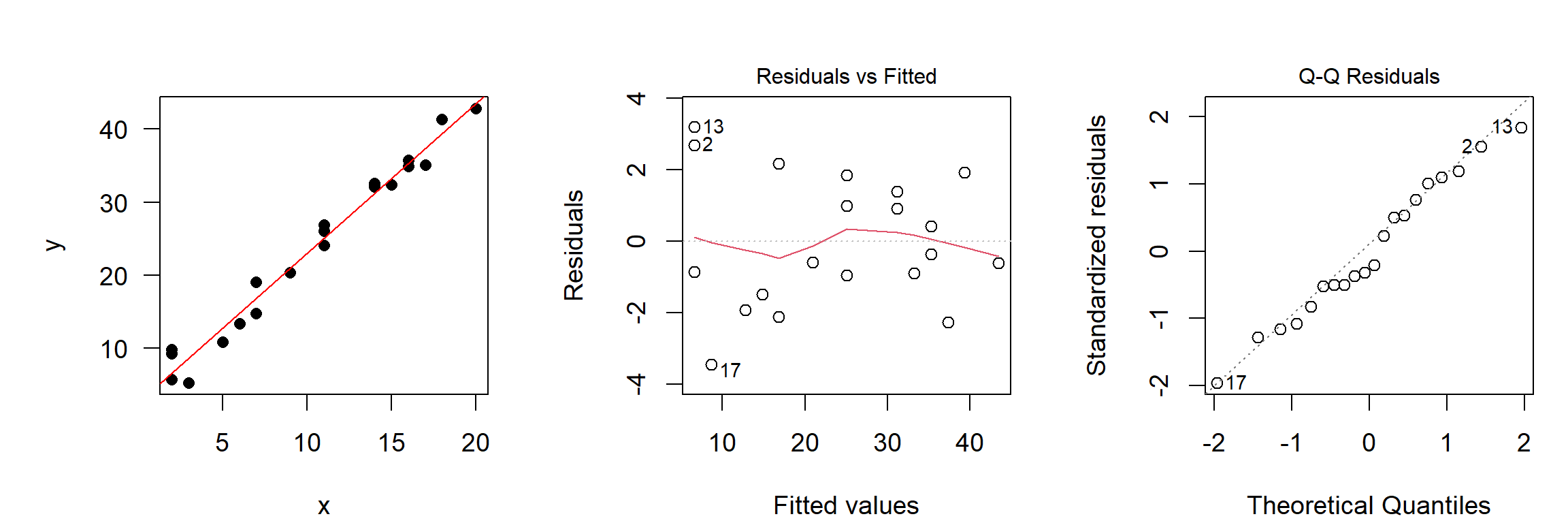
Keine Regressionsanalyse ohne grafische Diagnostik!
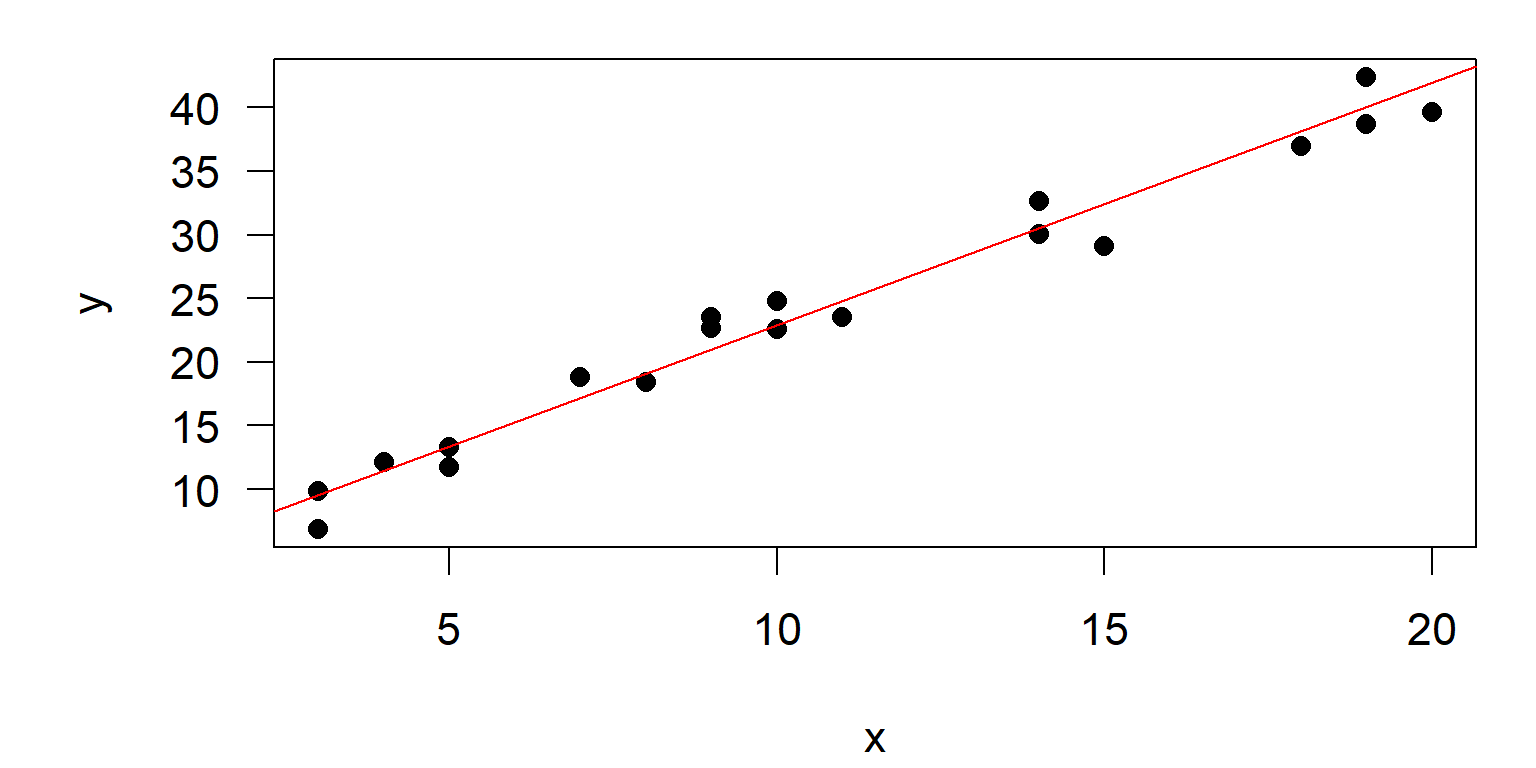
- x-y-Plot mit Regressionsgerade: ist die Varianz homogen?
- Plot der Residuen vs. gefittet: gibt es noch irgendwelche Restmuster?
- Q-Q- Plot, Histogramm: Ist die Verteilung der Residuen näherungsweise normal?
Prüfe annähernde Normalität grafisch, vertraue nicht auf Shapiro-Wilks.
Konfidenzintervall und Vorhersageintervall
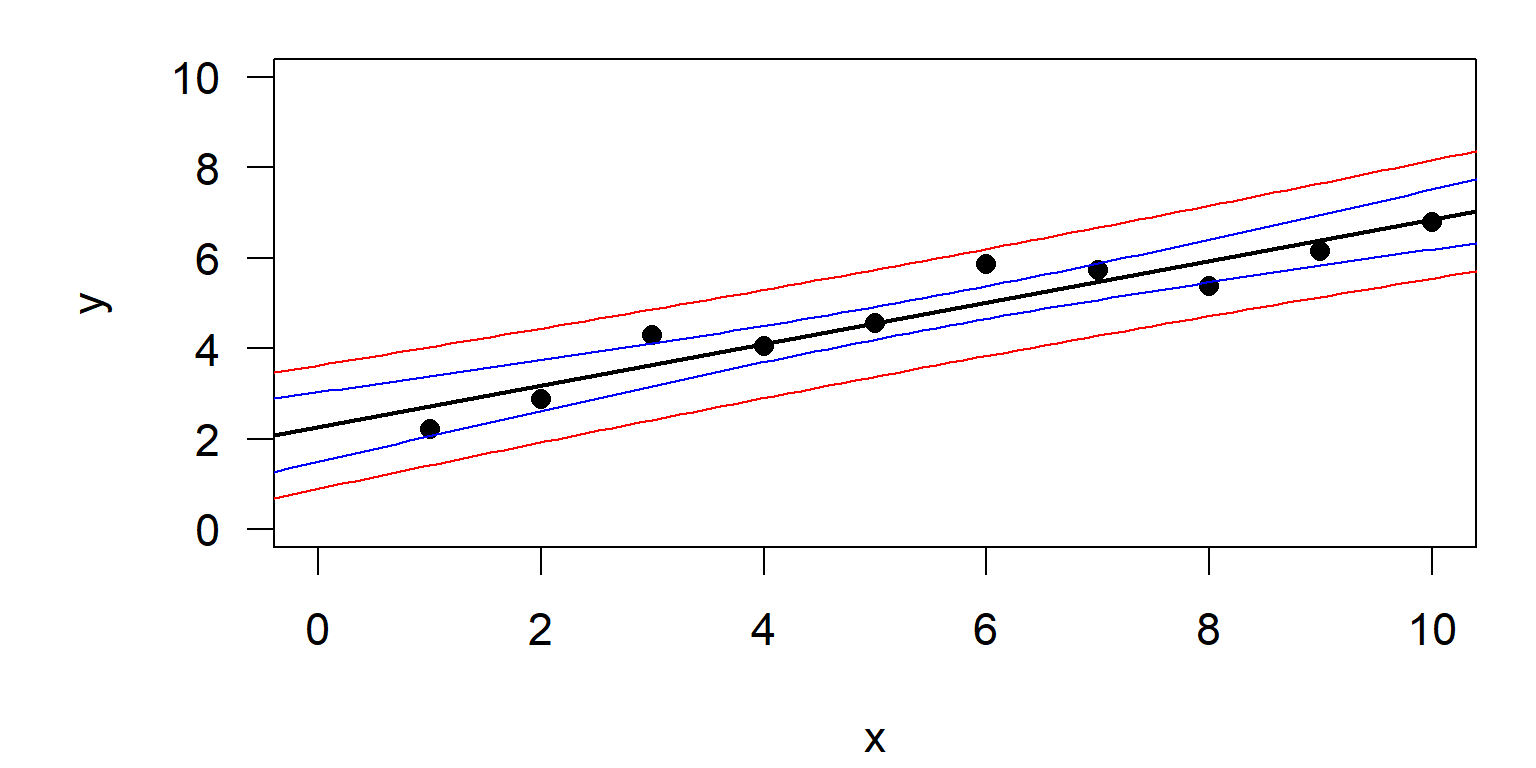
- Konfidenzintervall:
- Zeigt den Bereich, in dem die „wahre Regressionslinie“ zu 95 % erwartet wird.
- Die Breite dieses Bereichs nimmt mit zunehmendem \(n\) ab.
- analog zum Standardfehler
- Vorhersageintervall:
- Zeigt den Bereich, in dem die Vorhersage für einen einzelnen Wert (zu 95%) erwartet wird.
- Die Breite ist unabhängig vom Stichprobenumfang \(n\).
- analog zur Standardabweichung
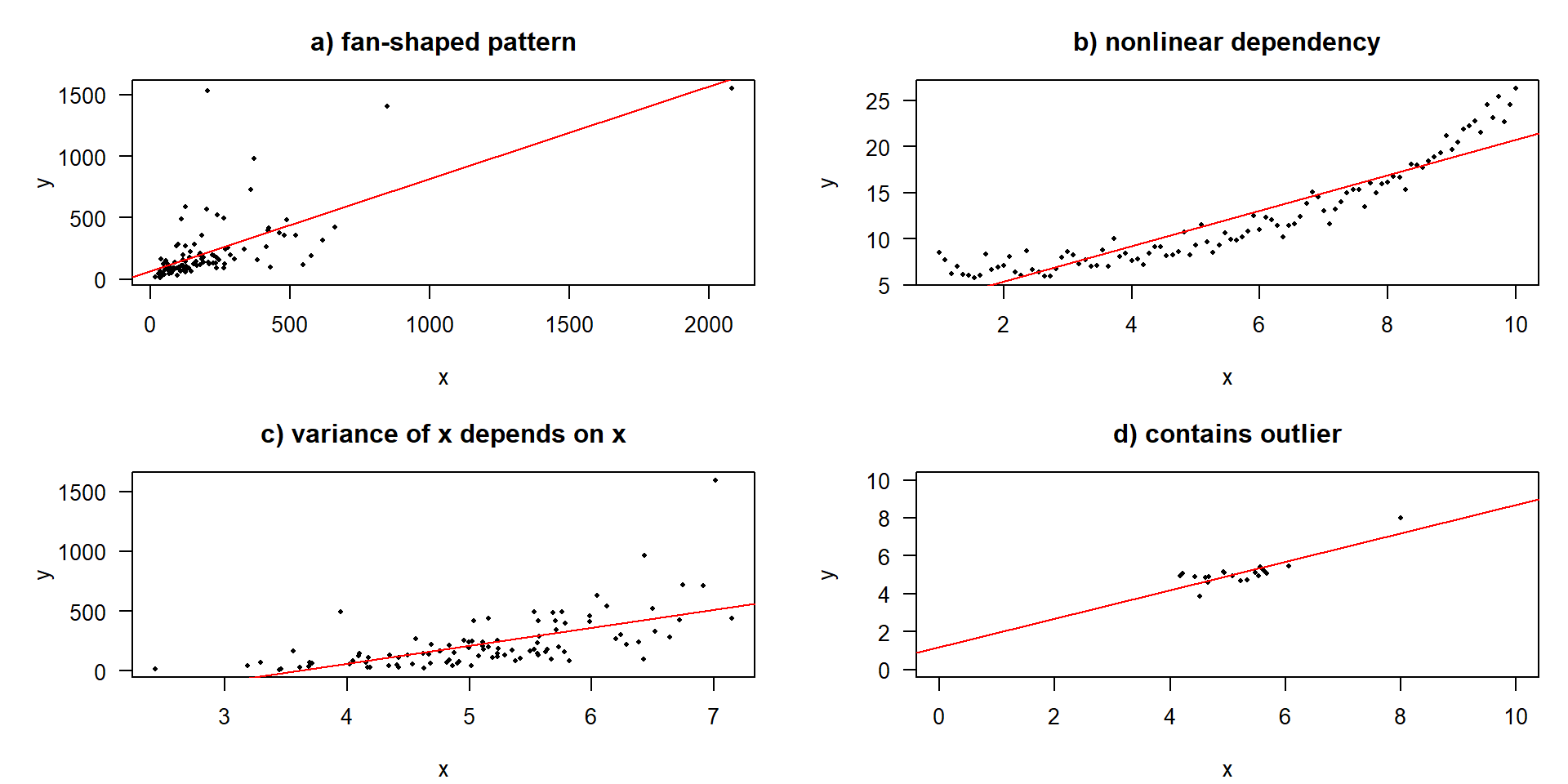
Problemfälle
Robuste Regression mit IWLS
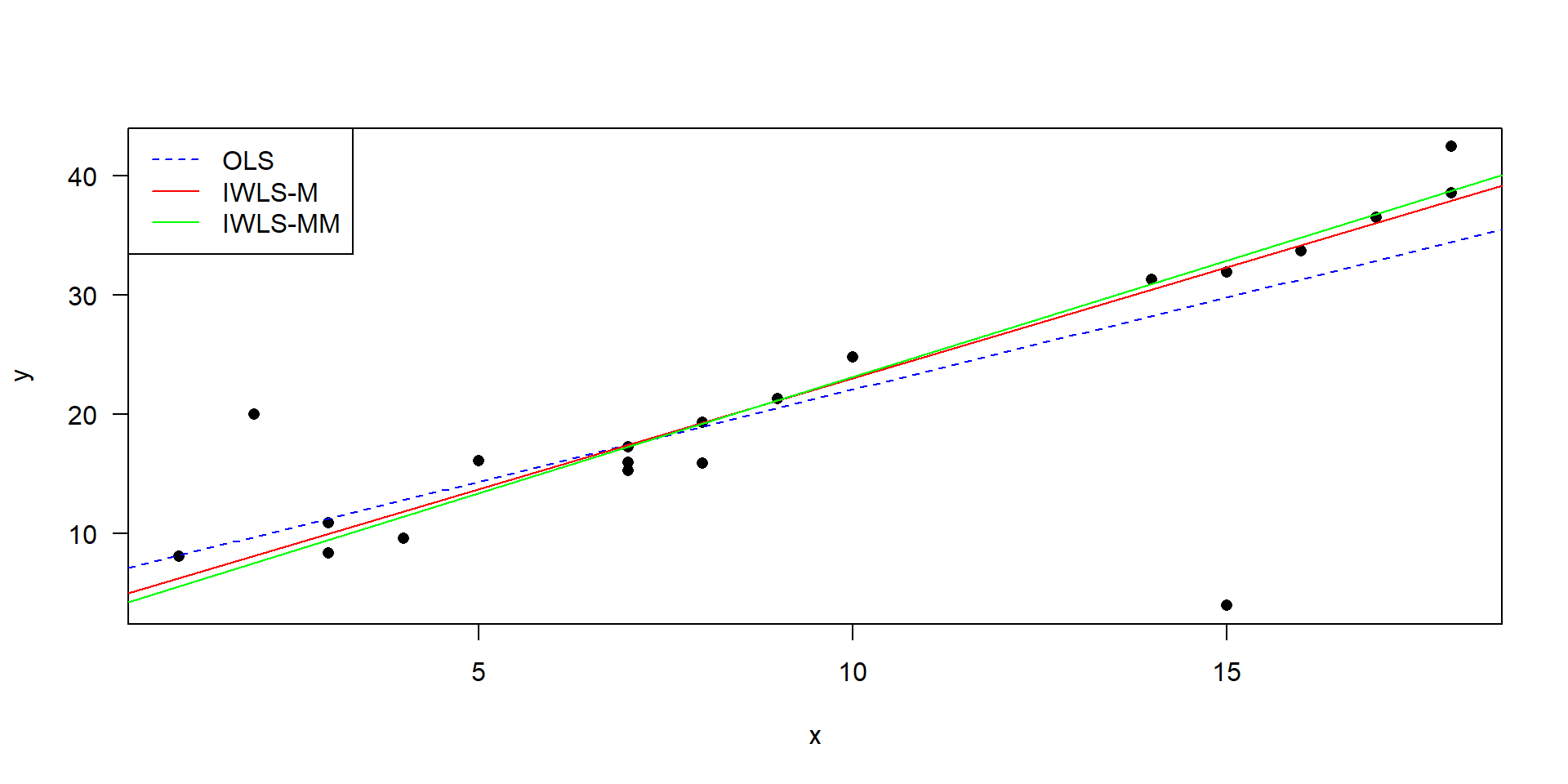
- OLS (gewöhnliche kleinste Quadrate, engl. ordinary least squares) ist die „normale“ Regression.
- IWLS: iterated re-weighted least squares
- M- bzw. MM-Schätzung: zwei verschiedene Ansätze, Details in Venables & Ripley (2013)
- robuste Regression ist dem Ausschluss von Ausreißern vorzuziehen