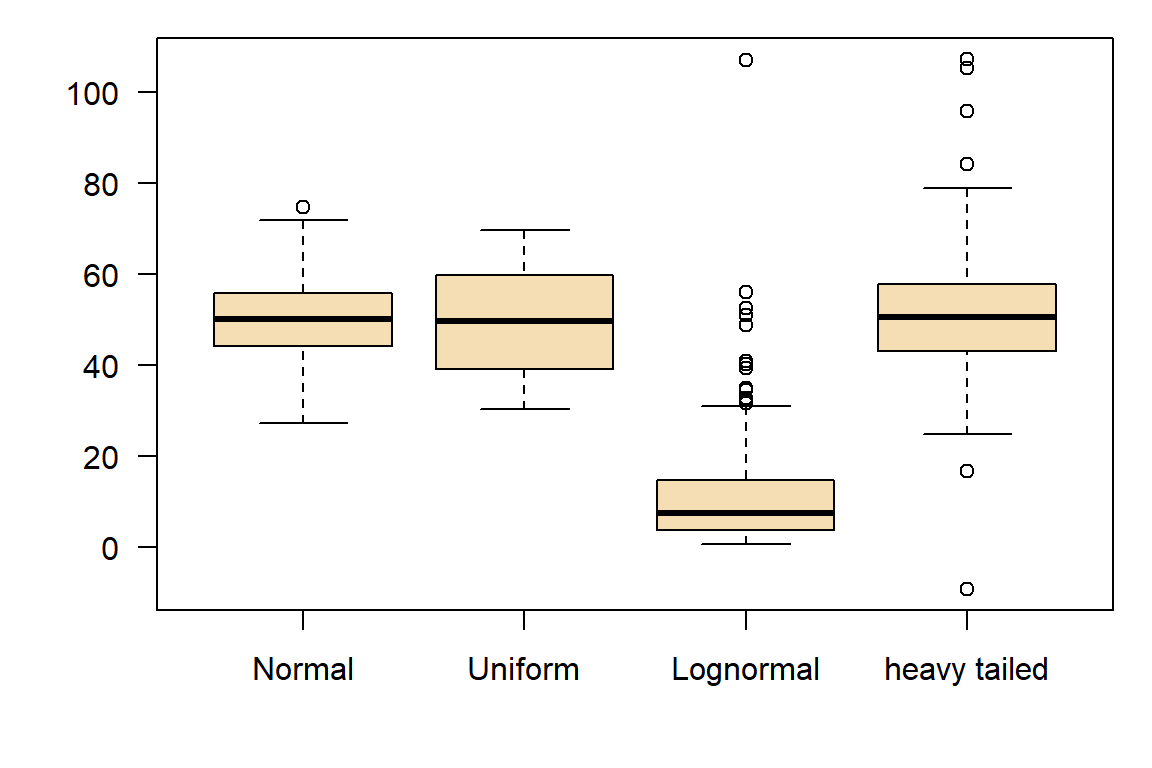
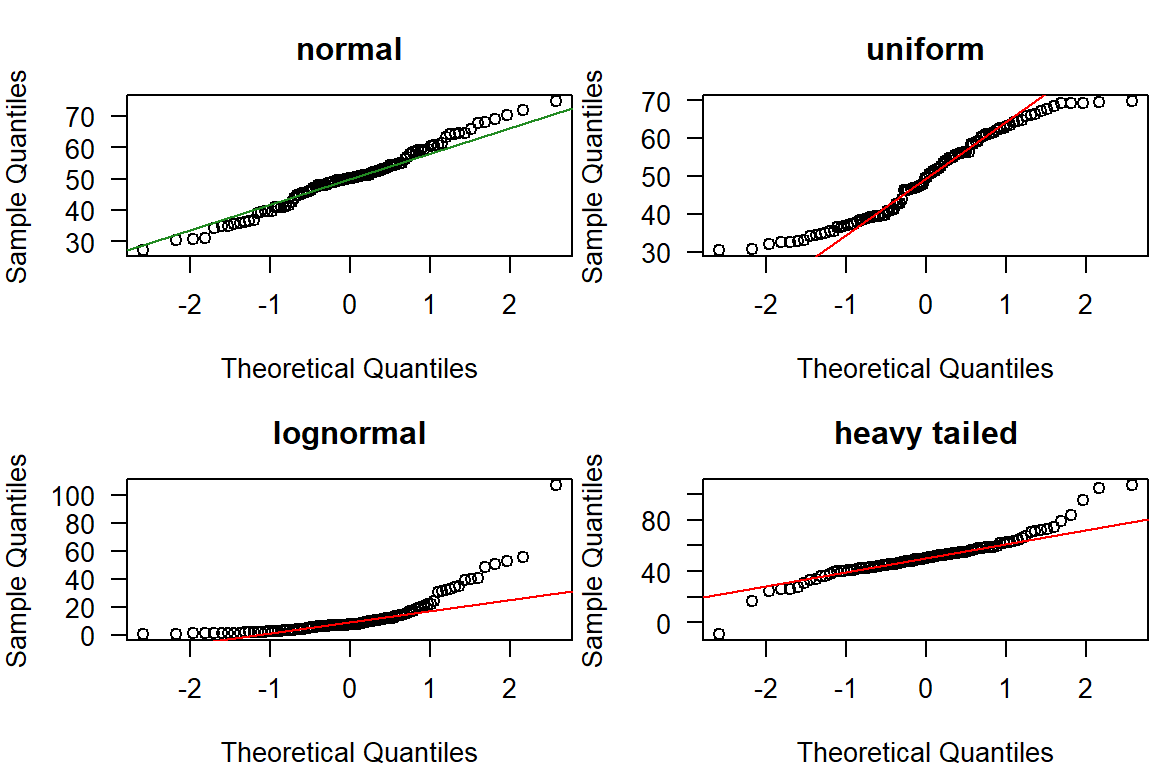
Ein statistischer Test hilft zu entscheiden, ob eine Hypothese wahrscheinlich richtig ist oder nicht, basierend auf vorliegenden Daten.
Beispiel: Wir vergleichen zwei Stichproben oder eine Stichprobe mit einem statistischen Modell.
Dazu stellen zwei Hypothesen auf:
Alternativhypothese (\(H_a\)): Das ist unsere eigentliche Hypothese, dass es einen Unterschied oder eine Beziehung gibt.
Nullhypothese (\(H_0\)): Wir nehmen an, dass es keinen Unterschied oder keine Beziehung gibt und testen, ob wir diese Hypothese ablehnen können.
Statistisch signifikant bedeutet: Die Wahrscheinlichkeit, dass wir unsere Beobachtung nur durch puren Zufall gemacht haben, ist sehr gering. Wenn das so ist, sagen wir, dass unser Ergebnis signifikant ist und \(H_a\) unterstützt wird.
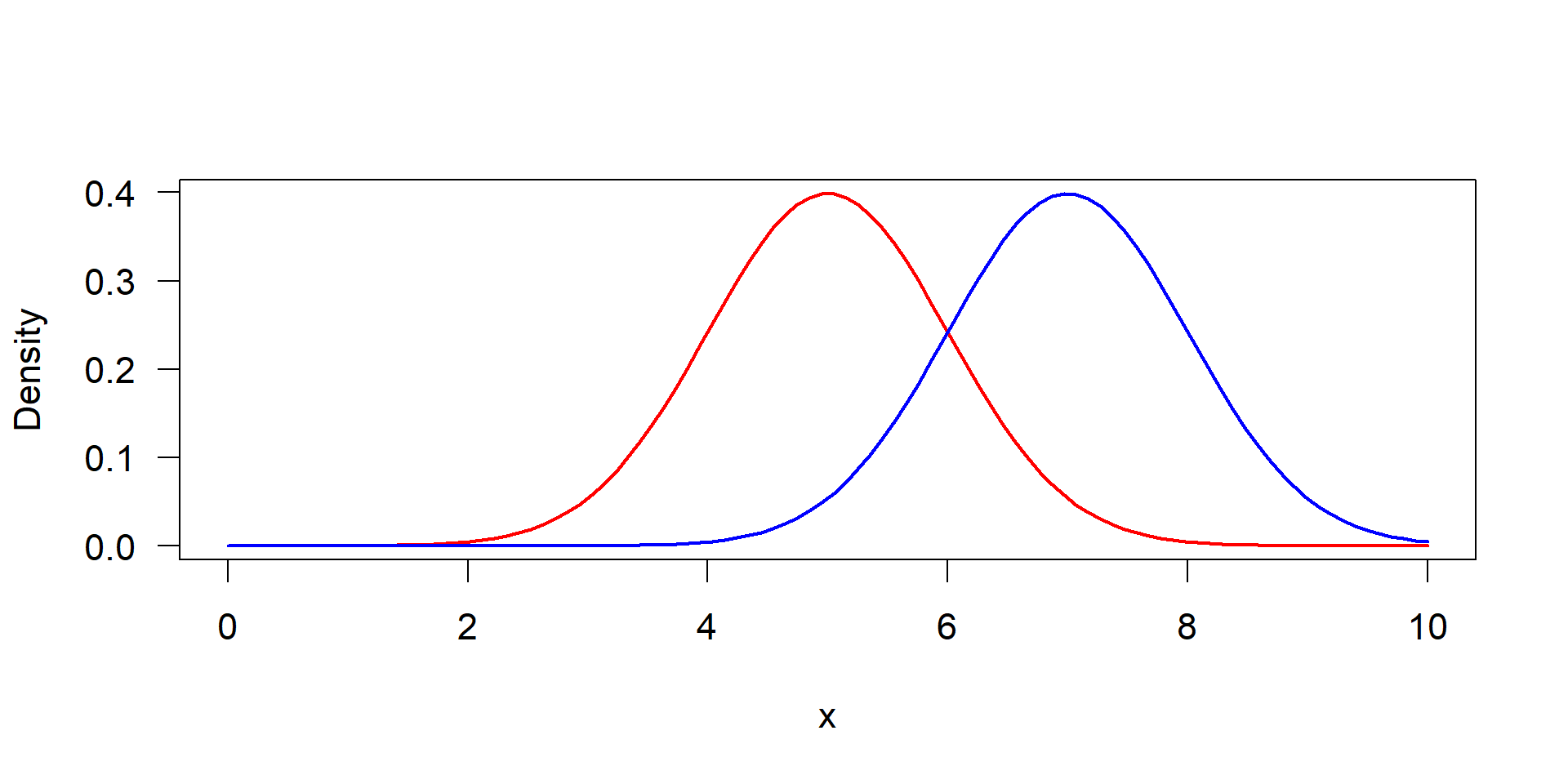
Mittelwerte von zwei Grundgesamtheiten \(\mu_1, \mu_2\)
absolute Effektstärke \(\Delta\)
relative Effektstärke \(\delta\) (auch Cohen’s d genannt)
Signifikanz bedeutet, dass es unwahrscheinlich ist, dass ein beobachteter Effekt das Ergebnis einer reinen Zufallsvariation ist.
Nullhypothese und Alternativhypothese
\(H_0\) Nullhypothese: Zwei Grundgesamtheiten unterscheiden sich nicht in Bezug auf eine bestimmte Eigenschaft.
Annahme: Der beobachtete Effekt ist rein zufällig entstanden, der wahre Effekt ist Null.
\(H_a\) Alternativhypothese (Versuchshypothese): Vorhandensein eines bestimmten Effekts.
Eine Alternativhypothese ist nie vollständig wahr oder „bewiesen“.
Die Annahme von \(H_A\) bedeutet nur, dass \(H_0\) unwahrscheinlich ist.
„Nicht signifikant“ bedeutet entweder kein Effekt oder Stichprobengröße zu klein!
Anmerkung: Unterschiedliche Bedeutung von Signifikanz (\(H_0\) unwahrscheinlich) und Relevanz (Effekt groß genug, um in der Praxis eine Rolle zu spielen).
Der p-Wert
Die Interpretation des p-Wertes war in der Vergangenheit oft verwirrend, selbst in Statistik-Lehrbüchern, so dass es gut ist, sich auf eine klare Definition zu beziehen:
Der p-Wert ist definiert als die Wahrscheinlichkeit, ein Ergebnis zu erhalten, das gleich oder „extremer“ ist als das, was tatsächlich beobachtet wurde, wenn die Nullhypothese wahr ist.
Hubbard (2004) Alphabet Soup: Blurring the Distinctions Between p’s and a’s in Psychological Research, Theory Psychology 14(3), 295-327. DOI: 10.1177/0959354304043638
Alpha- und Beta-Fehler
Realität
Entscheidung des Tests
Richtig?
Wahrscheinlichkeit
\(H_0\) = wahr
signifikant
nein
\(\alpha\)-Fehler
\(H_0\) = falsch
nicht signifikant
nein
\(\beta\)-Fehler
\(H_0\) = wahr
nicht signifikant
ja
\(1-\alpha\)
\(H_0\) = falsch
signifikant
ja
\(1-\beta\) (Trennschärfe)
1.\(H_0\) fälschlicherweise abgelehnt (Fehler erster Art oder \(\alpha\)-Fehler)
es wird ein Effekt behauptet, den es nicht gibt, z.B. ein Medikament, das keine Wirkung hat
2.\(H_0\) fälschlicherweise beibehalten (Fehler zweiter Art oder \(\beta\)-Fehler)
typischer Fall in kleinen Studien, bei denen die Wirkung nicht ausreicht, um vorhandene Effekte zu erkennen
Verwendung in der Praxis
übliche Konvention in den Umweltwissenschaften: \(\alpha=0.05\), muss vorher festgelegt werden
\(\beta=f(\alpha, \text{Effektstärke}, \text{Stichprobengröße},
\text{Art des Tests})\), sollte \(\le 0.2\) sein
Signifikanz und Relevanz
Statistische Signifikanz: die Nullhypothese \(H_0\) ist im statistischen Sinne unwahrscheinlich.
Praktische Relevanz (manchmal auch „praktische Signifikanz“ genannt): die Effektstärke ist groß genug, um in der Praxis eine Rolle zu spielen.
Ob ein Effekt relevant sein kann oder nicht, hängt also von seiner Effektstärke und dem Anwendungsbereich ab.
Betrachten wir zum Beispiel eine Impfung. Wenn ein Impfstoff in einem klinischen Test eine signifikante Wirkung hat, aber nur 10 von 1000 Menschen schützt, würde man diesen Effekt nicht als relevant ansehen und diesen Impfstoff nicht herstellen.
Andererseits können auch kleine Wirkungen von Bedeutung sein. Wenn also eine toxische Substanz bei 1 von 1000 Personen Krebs auslösen würde, würden wir das als relevant betrachten. Um es auch als signifikant zu erkennen, ist eine epidemiologische Studie mit einer großen Anzahl von Menschen erforderlich. Da es sich aber um eine hochrelevante Wirkung handelt, lohnt sich der Aufwand.
Take home messages
Ein p-Wert misst die Wahrscheinlichkeit, dass ein rein zufälliger Effekt gleich groß oder größer ist als ein beobachteter Effekt, wenn die Nullhypothese wahr ist.
Signifikant, die Ergebnisse sind unwahrscheinlich, wenn es keinen echten Effekt gäbe.
Nicht signifikant bedeutet nicht „kein Effekt“.
Nicht signifikante Ergebnisse deuten auf die Notwendigkeit weiterer Untersuchungen hin:
Vergrößerung der Stichprobe
Erhöhung des experimentellen Effekts
Reduzierung des experimentellen Fehlers
Wahl eines leistungsfähigeren statistischen Verfahrens
Wichtig: Konzentriere Dich nicht nur auf p-Werte und Signifikanz!
Vergiss nie, Stichprobengröße, Effektstärke und Relevanz anzugeben.
Bei großen Datensätzen:
Statistisch signifikante Ergebnisse können leicht auch für sehr kleine und praktisch irrelevante Effekte erzielt werden.
\(\rightarrow\) Effektstärke und Relevanz werden wichtiger als p-Werte.
Differenzen zwischen Mittelwerten
Einstichproben-t-Test
prüft, ob eine Stichprobe aus einer Grundgesamtheit mit gegebenem Mittelwert \(\mu\) stammt
basiert auf der Prüfung, ob der Mittelwert der Grundgesamtheit \(\mu\) im Konfidenzintervall von \(\bar{x}\) liegt
Angenommen, wir haben eine Stichprobe mit dem Umfang \(n=10, \bar{x}=5.5, s=1\) und \(\mu=5\).
Nun schätzen wir das 95%-Konfidenzintervall von \(\bar{x}\):
\[
CI = \bar{x} \pm t_{1-\alpha/2, n-1} \cdot s_{\bar{x}}
\] mit \[
s_{\bar{x}} = \frac{s}{\sqrt{n}} \qquad \text{(Standardfehler)}
\]
Auf den folgenden Folien werden unterschiedliche Berechnungsmethoden vorgestellt.
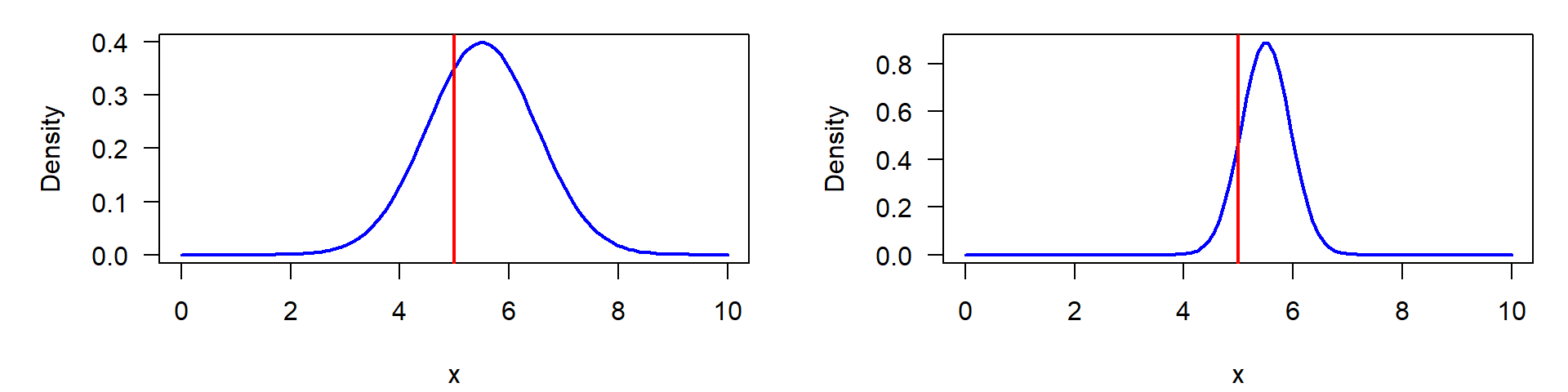
Zur Erinnerung: Standardabweichung und Standardfehler
Visualisierung eines Einstichproben-t-Test. Links: ursprüngliche Verteilung der Daten, gemessen an der Standardabweichung, rechts: Verteilung der Mittelwerte, gemessen an ihrem Standardfehler.
One Sample t-test
data: x
t = 1.5811, df = 9, p-value = 0.1483
alternative hypothesis: true mean is not equal to 5
95 percent confidence interval:
4.784643 6.215357
sample estimates:
mean of x
5.5
Der Test liefert den beobachteten t-Wert, das 95%-Konfidenzintervall und den p-Wert.
Ein wichtiger Unterschied ist, dass diese Methode mit den Originaldaten arbeitet, während die anderen Methoden nur Mittelwert, Standardabweichung und Stichprobenumfang benötigen.
Zweistichproben-t-Test
Der Zweistichproben-t-Test vergleicht zwei unabhängige Stichproben:
Welch Two Sample t-test
data: x1 and x2
t = -3.7185, df = 21.611, p-value = 0.001224
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.3504462 -0.6662205
sample estimates:
mean of x mean of y
5.475000 6.983333
\(\rightarrow\) beide Stichproben unterscheiden sich signifikant (\(p < 0,05\))
Anmerkung: R hat hier nicht den „normalen“ t-Test durchgeführt, sondern den Welch-Test (= heteroskedastischer t-Test),
bei dem die Varianzen der beiden Stichproben nicht gleich sein müssen.
Hypothese und Formel für den Zweistichproben-t-Test
\(H_0\)\(\mu_1 = \mu_2\)
\(H_a\) die beiden Mittelwerte sind unterschiedlich
Welch Two Sample t-test
data: x1 and x2
t = -3.7185, df = 21.611, p-value = 0.001224
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.3504462 -0.6662205
sample estimates:
mean of x mean of y
5.475000 6.983333
… das ist die Standardmethode der t.test-Funktion.
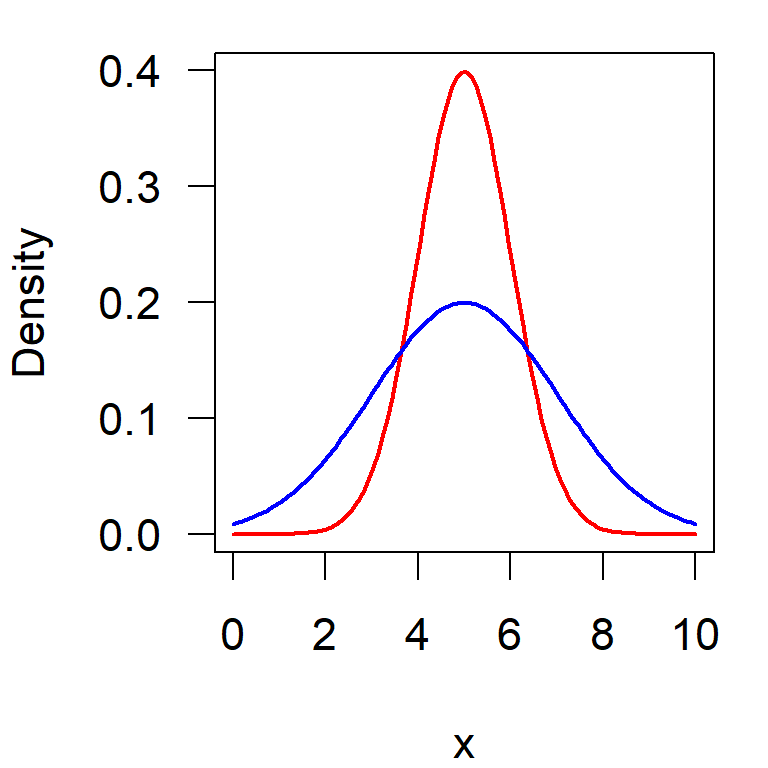
Test auf Varianzgleichheit: F-Test
\(H_0\): \(\sigma_1^2 = \sigma_2^2\)
\(H_a\): Varianzen ungleich
Testkriterium:
\[F = \frac{s_1^2}{s_2^2} \]
größere der beiden Varianzen im Zähler \((s^2_1 > s^2_2)\)
Freiheitsgrade (\(n-1\)) für Zähler und Nenner können verschieden sein
Two Sample t-test
data: x1 and x2
t = -1.372, df = 8, p-value = 0.2073
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4.28924 1.08924
sample estimates:
mean of x mean of y
4.0 5.6
Paired t-test
data: x1 and x2
t = -4, df = 4, p-value = 0.01613
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-2.710578 -0.489422
sample estimates:
mean difference
-1.6
p=0.016, signifikant
Der gepaarte t-Test besitzt in diesem Fall eine größere Power (Trennschärfe).
Mann-Whitney- und Wilcoxon-Test
Nichtparametrische Tests:
Keine Annahmen über Form und Parameter der Verteilung, aber
Verteilungen sollten ähnlich sein, sonst kann der Test irreführend werden.
Basierend auf Rängen: Die Tests vergleichen die Ränge der Daten.
Bezeichnung “Mann-Whitney” für unabhängige Stichproben, “Wilcoxon” für gepaarte Stichproben.
Grundprinzip: Zählung der so genannten „Inversionen“ der Ränge, d.h. wie oft sich die Reihenfolge der Stichproben überschneidet
Stichprobe A: 1, 3, 4, 5, 7
Stichprobe B: 6, 8, 9, 10, 11
Beide Stichproben gemeinsam geordnet: 1, 3, 4, 5, 6, 7, 8, 9, 10, 11
Inversionen: \(\rightarrow\)\(U = 1\)
Mann-Whitney-Test in der Praxis
Weise den beiden Stichproben \(A\) und \(B\) mit dem Stichprobenumfang \(m\) und \(n\) die Ränge \(R_A\) und \(R_B\) zu.
Berechne die Anzahl der Inversionen \(U\):
\[\begin{align*}
U_A &= m \cdot n + \frac{m (m + 1)}{2} - \sum_{i=1}^m R_A \\
U_B &= m \cdot n + \frac{n (n + 1)}{2} - \sum_{i=1}^n R_B \\
U &= \min(U_A, U_B)
\end{align*}\]
Kritische Werte von \(U\) finden sich in gängigen Statistik-Lehrbüchern.
In R nicht notwendig, p-Wert wird direkt ausgegeben.
Anmerkung: Verwende spezielle Version wilcox.exact mit Korrektur, wenn mehrfach gleiche Werte (Bindungen) vorliegen.
Mann-Whitney - Wilcoxon-Test in R
A <-c(1, 3, 4, 5, 7)B <-c(6, 8, 9, 10, 11)wilcox.test(A, B) # für gepaarte Daten optionales Argument `paired = TRUE` verwenden
Wilcoxon rank sum exact test
data: A and B
W = 1, p-value = 0.01587
alternative hypothesis: true location shift is not equal to 0
Mann-Whitney - Wilcoxon-Test mit Bindungskorrektur
wird angewendet, wenn die Rangunterschiede doppelte Werte enthalten
Die Trennschärfe eines t-Tests bzw. der Mindeststichprobenumfang kann mit der Funktion power.t.test() geschätzt werden:
power.t.test(n=5, delta=0.5, sig.level=0.05)
Two-sample t test power calculation
n = 5
delta = 0.5
sd = 1
sig.level = 0.05
power = 0.1038399
alternative = two.sided
NOTE: n is number in *each* group
\(\rightarrow\) ‘power’ = 0.10
Für \(n=5\) wird ein vorhandener Effekt von \(0.5 \sigma\) nur in 1 von 10 Fällen entdeckt.
Für eine Power von 80% bei \(n=5\) wird Effektstärke von mindestens \(2\sigma\) benötigt:
power.t.test(n=5, power=0.8, sig.level=0.05)
Für einen schwachen Effekt von \(0.5\sigma\) wird \(n\ge 64\) in jeder Gruppe benötig:
power.t.test(delta=0.5,power=0.8,sig.level=0.05)
\(\Rightarrow\) Man braucht entweder einen großen Stichprobenumfang oder einen starken Effekt.
Simulierte Power eines t-Tests
# Grundgesamtheitsparametern <-10xmean1 <-50; xmean2 <-55xsd1 <- xsd2 <-10alpha <-0.05nn <-1000# Anzahl an Testläufen der Simulationa <- b <-0# initialisiere Zählerfor (i in1:nn) {# erstelle Zufallszahlen x1 <-rnorm(n, xmean1, xsd1) x2 <-rnorm(n, xmean2, xsd2)# Ergebnisse des t-Tests p <-t.test(x1,x2,var.equal =TRUE)$p.value if (p < alpha) { a <- a+1 } else { b <- b+1 }}print(paste("a=", a, ", b=", b, ", a/n=", a/nn, ", b/n=", b/nn))
allgemeingültiges Verfahren, auch für andere Tests geeignet.
Test auf Verteilungen
Testen auf Verteilungen
Nominale Variablen
\(\chi^2\)-Test
Exakter Test von Fisher
Ordinale Variablen
Cramér-von-Mises-Test
\(\rightarrow\) stärker als \(\chi^2\) oder KS-Test
Metrische Skalen
Kolmogorov-Smirnov-Test (KS-Test)
Shapiro-Wilk-Test (für Normalverteilung)
Grafische Prüfungen
Mehrfeldertafeln für nominale Variablen
Werden für nominale (d. h. kategoriale oder qualitative) Daten verwendet.
Beispiele: Augen- und Haarfarbe, medizinische Behandlung und Anzahl der geheilten/nicht geheilten Personen
Wichtig: Verwende absolute Messwerte (echte Zahlen!), keine Prozentsätze oder andere berechnete Daten (also nicht etwa Biomasse pro Fläche)
Beispiel: Verteilung von Daphnien (Wasserflöhen) in den Wasserschichten eines Sees:
Klon
Obere Schicht
Tiefe Schicht
A
50
87
B
37
78
C
72
45
In der oberen Schicht wurden die Futteralgen bereits aufgefressen. Sie finden sich nur noch im sauerstoffarmen Tiefenwasser.
genetisch angepasste Klone mit höherem Hämoglobingehalt können in sauerstoffreies Wasser tauchen
Chi-squared test for given probabilities
data: obsfreq
X-squared = 13.647, df = 8, p-value = 0.09144
chisq.test(obsfreq, simulate.p.value =TRUE, B =1000)
Chi-squared test for given probabilities with simulated p-value (based
on 1000 replicates)
data: obsfreq
X-squared = 13.647, df = NA, p-value = 0.0969
Einstichproben\(\chi^2\)-Test. Er testet auf Gleichheit der Häufigkeit in allen Klassen.
Die simulationsbasierte Version des Tests (mit 1000 Wiederholungen) ist etwas genauer als der Standard-\(\chi^2\)-Test, aber beide sind nicht signifikant.
Cramér-von-Mises-Test
\[
T = n \omega^2 = \frac{1}{12n} + \sum_{i=1}^n \left[ \frac{2i-1}{2n}-F(x_i) \right]^2
\]
## erstelle kumulative Verteilung mit identischer Wahrscheinlichkeit für alle Fällecdf <-stepfun(1:9, cumsum(c(0, rep(1/9, 9))))cdf <-ecdf(1:9)## führe den Test durchcvm.test(x, cdf)
Cramer-von Mises - W2
data: x
W2 = 0.51658, p-value = 0.03665
alternative hypothesis: Two.sided
Der Cramér-von-Mises-Test arbeitet mit den ursprünglichen, nicht in klassen eingeteilten Werten.
Verwendung der kumulativen Verteilungsfunktion berücksichtigt die Reihenfolge der Klassen\(\rightarrow\) leistungsfähiger als \(\chi^2\)-Test.
Testen auf Normalverteilung
Testen oder Prüfen?
Philosophisches Problem: Wir wollen \(H_0\)behalten!
Gleichheit kann nicht getestet werden \(\rightarrow\) deshalb graphisch prüfen
Plausibilitätsprüfung: Vor der Analyse nachdenken!
Was ist der Prozess der Datenerzeugung \(\rightarrow\) fachlicher Kontext?
Macht die Normalverteilung für die Daten „Sinn“?
Sind die Daten metrisch (kontinuierlich)?
Ist der Variationskoeffizient \(cv=s/\bar{x}\) < 0.33 (oder zumindest < 0.5)? Wenn die Daten zu nahe an der Null liegen: rechtsschiefe Verteilung wahrscheinlich.
Intrinsische Nicht-Normalität
Einige Datentypen, wie z. B. Zähldaten (z. B. Anzahl der Vorkommnisse) oder binäre Daten (z. B. Ja/Nein), sind von Natur aus nicht normalverteilt.
Binäre Daten: Arbeite mit Originaldaten und Binomialverteilung statt Prozentzahlen.
Zähldaten: Nutze Methoden für die Poisson-Verteilung.
Shapiro-Wilk-W-Test ?
\(\rightarrow\) Ziel: prüft, ob eine Stichprobe aus einer Normalverteilung stammt
x <-rnorm(100)shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.99064, p-value = 0.7165
\(\rightarrow\) der \(p\)-Wert ist größer als 0.05, also würden wir \(H_0\) behalten und schlussfolgern, dass nichts gegen die Annahme der Normalität spricht
Die Interpretation des Shapiro-Wilk-Tests ist mit Vorsicht zu betrachten:
für kleine \(n\) nicht empfindlich genug
bei großem \(n\) überempfindlich
Formale Tests, wie Shapiro-Wilk, \(\chi^2\)- (Chi-Quadrat-) oder Kolmogorov-Smirnov, werden zur Überprüfung der Normalitätsannahme für t-Tests und ANOVA nicht mehr empfohlen.
\(x\): theoretische Quantile, wo die Werte bei Vorliegen einer Normalverteilung gefunden werden sollten
\(y\): normalisierte und geordnete Messwerte (\(z\)-Werte)
skaliert in der Einheit der Standardabweichungen
Normalverteilung liegt vor, wenn die Punkte einer Geraden folgen
Prüfung der Verteilung für deskriptive Zwecke
In manchen Disziplinen, z.B. in der Hydrologie, möchte man gelegentlich wissen, welcher Verteilungstyp einen Datensatz am besten beschreibt. Ein Beispiel ist die Extremwertanalyse (z.B. 100-jähriges Hochwasser), da hier das Central Limit Theorem (CLT) nicht greift.
Vorgehensweise
Visuelle Prüfung (besonders auf die tails achten)
Histogramm (erster Eindruck)
Q-Q-Plots (genauere Passform)
Formale Tests zur Ergänzung (Ausschlussprinzip)
Tests: Kolmogorov-Smirnov, Cramér-von Mises oder Anderson-Darling
Ablehnung des Verteilungstyps bei signifikantem \(p < 0.05\).
Modellselektion
Nutzung von AIC/BIC zur Identifikation des optimalen Modells
Berücksichtigung der physikalischen Plausibilität der Parameter
Transformationen
Transformationen
Ermöglicht die Anwendung von Methoden, die für normalverteilte Daten entwickelt wurden, auf nicht-normalverteilte Fälle.
Einige moderne Methoden (z. B. verallgemeinerte lineare Modelle, GLM) können bestimmte Verteilungen direkt verarbeiten, z.B. Binomial-, Gamma- oder Poisson-Verteilung.
Transformationen für rechtsschiefe Daten
\(x'=\log(x)\)
\(x'=\log(x + a)\)
\(x'=(x+a)^c\)(\(a\) zwischen 0,5 und 1)
\(x'=1/x\)(„sehr stark“, d.h. in den meisten Fällen zu extrem)
\(x'=a - 1/\sqrt{x}\)(um die Skalierung zu vereinfachen)
\(x'=1/\sqrt{x}\)(Kompromiss zwischen \(\ln\) und \(1/x\))
\(x'=a+bx^c\)(sehr allgemein, schließt Potenzen und Wurzeln ein)
In vielen praktischen Fällen kann man statt \(\frac{y^\lambda - 1}{\lambda}\) vereinfacht \(y^\lambda\) verwenden.
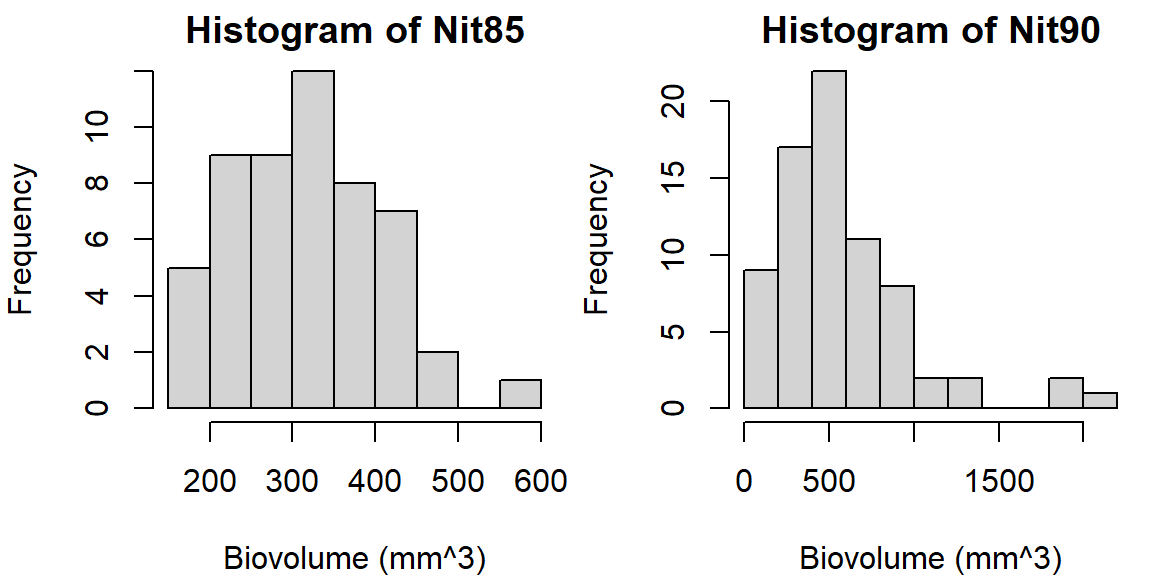
library(MASS)boxcox(Nit90 ~1)
Argument von boxcox ist eine sogenannte „Modellformel“ oder das Ergebnis eines linearen Modells (lm)
Die einfachste Form ist das „Nullmodell“ ohne Erklärungsvariablen (~ 1).
Mehr über Modellformeln, siehe ANOVA Kapitel.
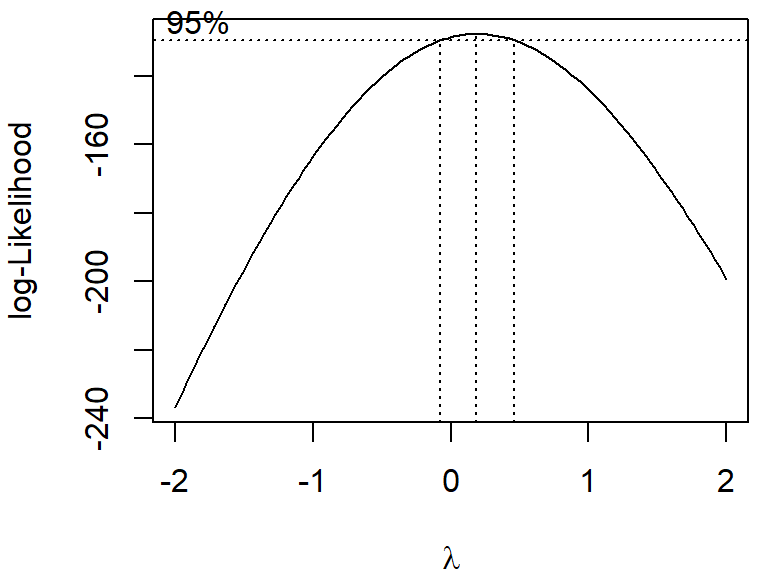
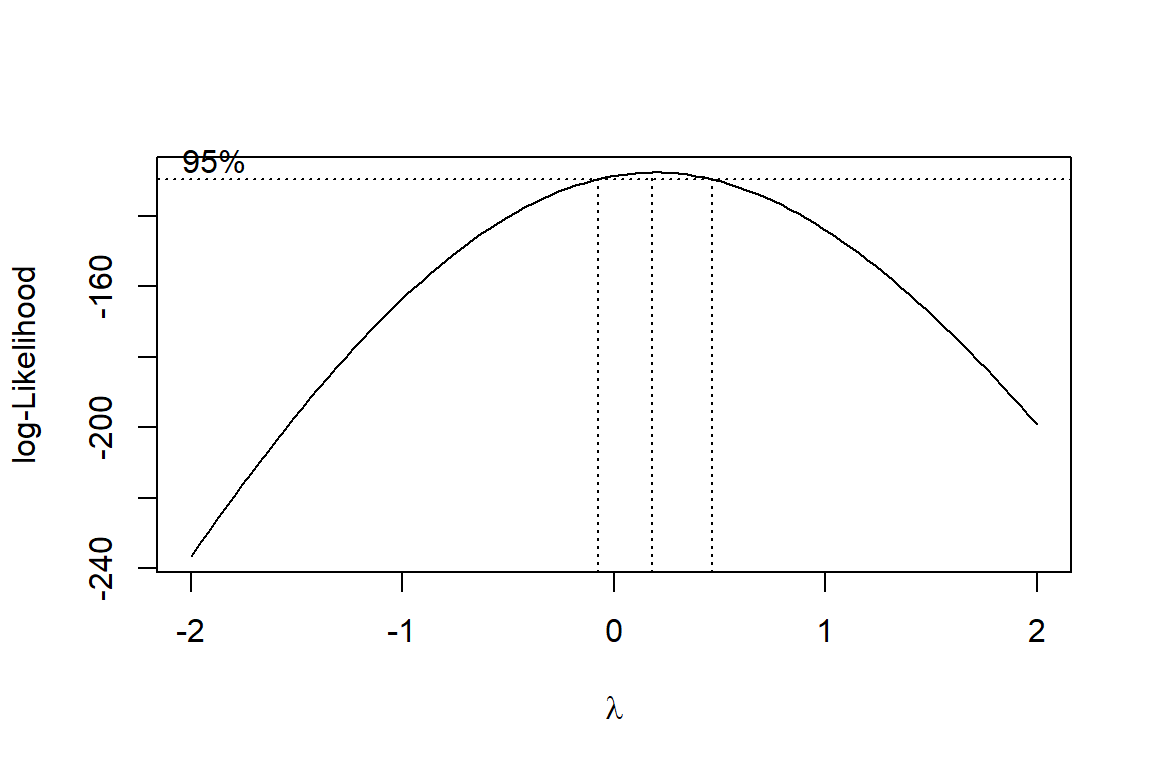
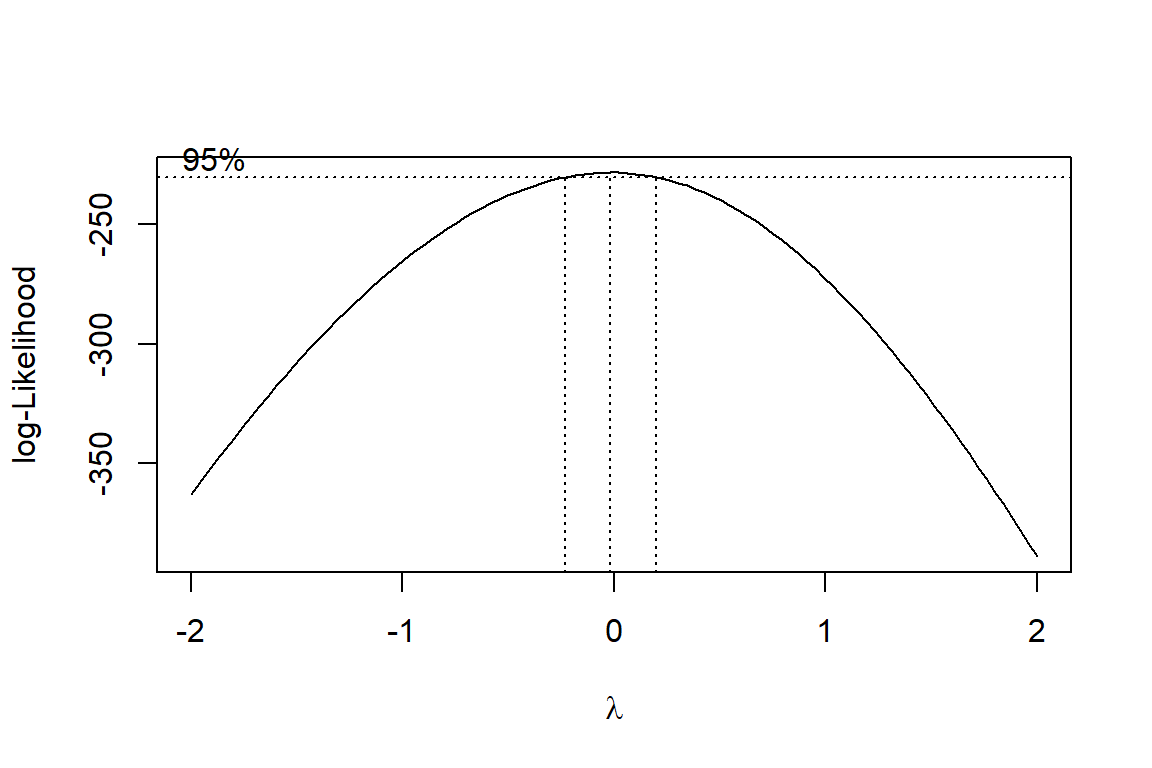
Box-Cox Methode: Ergebnisse
Interpretation
Die gepunkteten vertikalen Linien und die horizontale 95%-Linie zeigen die Vertrauensgrenzen für mögliche Transformationen.
Die Zahlen sind angenähert \(\rightarrow\) eine Dezimalstelle genügt.
Hier können wir entweder eine log-Transformation (\(\lambda=0\)) oder eine Potenz von \(\approx 0.5\) verwenden.
Direkte Ermittlung des Zahlenwerts:
bc <-boxcox(Nit90 ~1)
str(bc)
List of 2
$ x: num [1:100] -2 -1.96 -1.92 -1.88 -1.84 ...
$ y: num [1:100] -237 -233 -230 -226 -223 ...
bc$x[bc$y ==max(bc$y)]
[1] 0.1818182
Test von gepoolten Stichproben mit unterschiedlichen Mittelwerten
boxcox(biovol ~ group, data = dat)
Um die gemeinsame Verteilung aller Gruppen auf einmal zu testen, gibt man die Erklärungsvariablen auf der rechten Seite der Modellformel an: biovol ~ group
Die optimale Transformation für beide Stichproben zusammen ist log.
verteilungsfrei (erfordert keine Normalverteilung),
erkennt jegliche monotone Abhängigkeit,
wird durch Ausreißer kaum beeinträchtigt.
Nachteile:
gewisser Informationsverlust aufgrund der Rangbildung,
keine Informationen über die Art der Abhängigkeit,
keine direkte Beziehung zum Bestimmtheitsmaß.
Fazit: \(r_s\) ist dennoch sehr empfehlenswert!
Korrelationskoeffizienten in R
Pearson’s Produkt-Moment-Korrelationskoeffizient
Spearman’s Rangkorrelationskoeffizient
x <-c(1, 2, 3, 5, 7, 9)y <-c(3, 2, 5, 6, 8, 11)cor.test(x, y, method="pearson")
Pearson's product-moment correlation
data: x and y
t = 7.969, df = 4, p-value = 0.001344
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.7439930 0.9968284
sample estimates:
cor
0.9699203
Wenn Linearität oder Normalität der Residuen zweifelhaft sind, verwende eine Rangkorrelation
cor.test(x, y, method="spearman")
Spearman's rank correlation rho
data: x and y
S = 2, p-value = 0.01667
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.9428571
Problemfälle
Ausblick: Mehr als zwei unabhängige Variablen
Multiple Korrelation
Beispiel: Chl-a=\(f(x_1, x_2, x_3, \dots)\), wobei \(x_i\) = Biomasse der \(i\)-ten Phytoplanktonart.
multipler Korrelationskoeffizient
partieller Korrelationskoeffizient
Attraktive Methode \(\leftrightarrow\), aber in der Praxis schwierig:
„unabhängige“ Variablen können miteinander korrelieren (Multikollinearität) \(\Rightarrow\) Verzerrung des Vielfachen \(r\).
Nichtlinearitäten sind noch schwieriger zu handhaben als im Fall von zwei Stichproben.
Empfehlung:
Verwende multivariate Methoden (NMDS, PCA, …) für einen ersten Überblick,
Wende die multiple Regression mit Sorgfalt an und nutze Prozesswissen.
Literatur
Hubbard, R. (2004). Alphabet soup: Blurring the distinctions between p’s and a’s in psychological research. Theory & Psychology, 14(3), 295–327. https://doi.org/10.1177/0959354304043638
Zimmerman, D. W. (2004). A note on preliminary tests of equality of variances. British Journal of Mathematical and Statistical Psychology, 57(1), 173–181. https://doi.org/10.1348/000711004849222